本篇文章观点仅限于目前的理解,后续若有新的理解,还会继续更新。
1. Introduce
Fast R-CNN是2015年发表在ICCV中的文章中提出的,作者的目的是对R-CNN中的一些问题进行改进,对整个框架的训练进行了简化,同时提高了检测速度和精度。
R-CNN的缺点很明显:
- 训练不能一次完成,需要分多步进行;
- 在图像上提取到的候选区域,每一个都需要经过CNN网络提出特征,计算上有重叠;
- 检测速度慢,基于VGG-16的网络在GPU上检测一张图片需要47s。
SPPnet是对R-CNN的一个改进,它对整张图片计算卷积特征,然后从这个共享的卷积特征中实现对物体的分类。SPPnet在测试阶段可加速R-CNN约10-100倍,且训练时间可减少3倍。
但SPPnet也有缺点,如训练仍需多个步骤、空间金字塔池化层无法反向传播训练等,基于这些缺点,作者提出了Fast R-CNN。
2. Overall Architecture
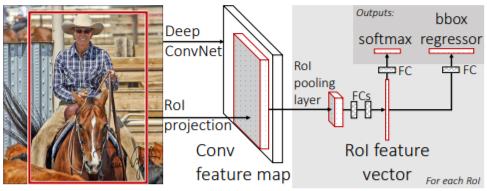
Fast R-CNN的整体框架如下图所示,检测步骤简述如下:
- Deep ConvNet对整张图像提取特征;
- 对每个候选区域,使用RoI pooling layer从CNN特征中提取出一个固定大小的特征向量;
- 该特征向量分别输入到两个全连接层,用于分类和定位。
这里的这张图片更为清晰地表达了Fast R-CNN的结构:
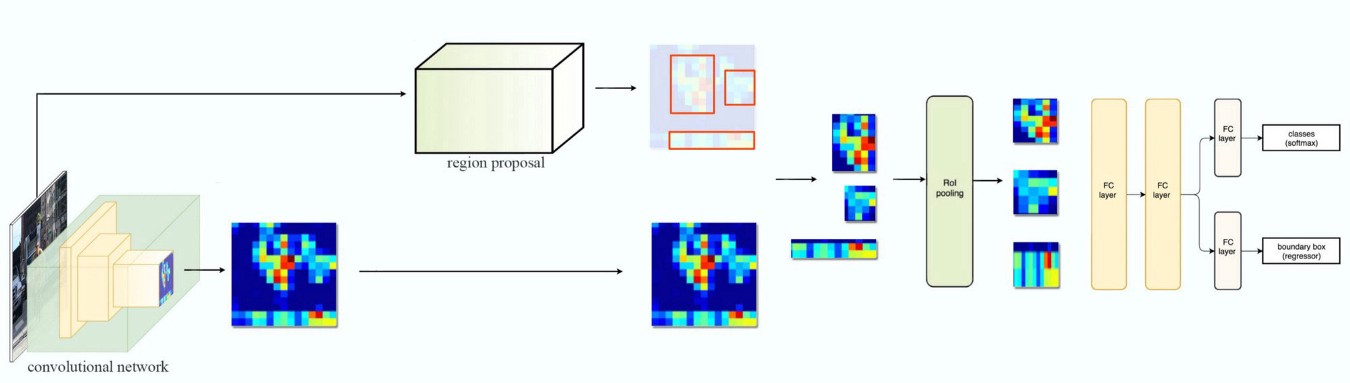
该框架借鉴了SPPnet中对整张图像提取特征的优点,同时舍弃了SVM,实现了端到端的训练和测试,大幅提升了训练和测试时的速度,检测一张图片仅需0.3s。
下面对该框架中的一些细节问题进行解释。
3. Initializing from pre-trained network
该框架中使用的CNN网络仍需要在ImageNet上进行预训练,当一个预训练的网络应用到Fast R-CNN中时,需要进行以下三点改进:
- 网络的最后一个max pooling layer 替换为RoI pooling layer,该RoI pooling layer输出
H*W的feature map以匹配后面的全连接层; - 网络中原有的全连接层被替换为两个全连接层,一个输出c+1类用于分类,一个用于边框位置的回归(每一类物体有一个边框回归器,一共c个);
- 网络可接收两类输入:图像数据和RoI位置信息。
4. RoI pooling layer
RoI pooling layer可视为一种更为通用的max pooling layer。
一个RoI区域表示为(r, c, h, w),其中(r, c)表示为左上角坐标,(h, w)表示为区域的高和宽。当一个这样的RoI区域输入RoI pooling layer时,该层根据固定的输出大小H*W来对h*w进行切分,并且在每个切分后的小格中使用最大池化(最大值作为当前格点的值)。使用该层的目的就是为了使RoI区域的特征大小适应后面的全连接层。
这里有一个疑问:假设我们通过Selective Search方法提取到一个RoI区域(r, c, h, w),当整张图像经过CNN网络提取特征后,该区域在CNN特征图上的大小及位置一定不是(r, c, h, w),所以输入进RoI pooling layer中的相应区域是什么?
目前的理解是:CNN网络中所有的卷积层使用padding以保证前后大小不变,仅在pooling层减小为1/2,若共有N个pooling层,则经过CNN网络后的feature map的长宽都是原图的1/N,则原图中的RoI区域(r, c, h, w)可在feature map上找到相应的区域与之对应。
5. Fine-tuning for detection
Mini-batch sampling
在精调网络参数时,作者在设置batch时,每次采样N张图像,每张图像中采样R/N个RoI区域,一共R个RoI区域为一个batch。为了充分利用共享特征,作者设置N=2,R=128。试想一下,每张图像采64个RoI要比64张图像中每张采一个RoI区域要快得多。
在一个mini-batch中,作者设置1/4的RoI为与ground truth的IOU>0.5的,这部分被标记为正样本,剩下的RoI选取IOU在0.1-0.5之间的,这部分RoI被标记为背景。
训练时,图像以0.5的概率水平翻转,不再使用其他图像增强技术。
Multi-task loss
在Fast R-CNN中,类别和位置进行同步训练,所以作者设计了一个联合损失函数。
对类别损失,L(p, u) = -log(p_u),其中u是真实的物体类别,p_u是网络输出的第u类的概率。
对位置损失,记背景为第0类,u为物体真实类别,t^u为第u类物体的回归器所预测的位置参数,v为真实的位置参数,为了降低对外点的敏感性,作者设计了如下损失函数:
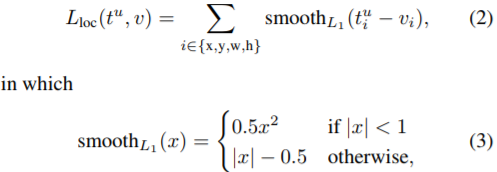
整体的损失函数为:
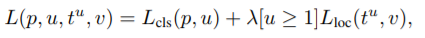 其中的λ是为了调节两种损失之间的权重,在论文中被设置为1。
其中的λ是为了调节两种损失之间的权重,在论文中被设置为1。
6. Conclusion
作者进行了一系列实验,得到的结论总结如下:
- 同时训练分类和位置回归器,提升了准确度
- 使用多尺度的图像金字塔,性能几乎没有提升
- 增加训练数据,精度有2%-3%的提升
- 网络直接输出的分类概率,效果比SVM略好
- 在图像中提取更多的候选框不能提升性能