本篇文章观点仅限于目前的理解,后续若有新的理解,还会继续更新。
0. Overview
R-CNN是于2014年CVPR上的一篇文章中提出的,在此之前,传统的目标检测方法如DPM等性能提升空间已经不大,也已经出现了OverFeat这样的基于深度学习的目标检测方法,(事实上在每一届的ILSVRC比赛上,经典的CNN模型论文中都有论述关于目标检测的部分),这里作者提出了自己的基于候选框的使用深度神经网络的目标检测方法,并在PASCAL VOC数据集上取得了当时的state-of-art效果。
如下图所示,R-CNN的总体思路并不复杂,总体上可分为四步:
- Region Proposal 生成:在输入图像上执行Selective Search方法,获取约2000个可能包含物体的候选区域;
- 特征提取:将这些候选区域resize到固定大小,输入经过ImageNet数据集预训练的CNN网络,提取固定长度的特征向量;
- 类别判断:将该特征向量输入线性SVM分类器,以判定相应候选区域的类别;
- box 位置精修:若区域包含物体,则使用一个经过预训练的Bounding-box Regression对box的坐标进行修正,得到最终的预测坐标;
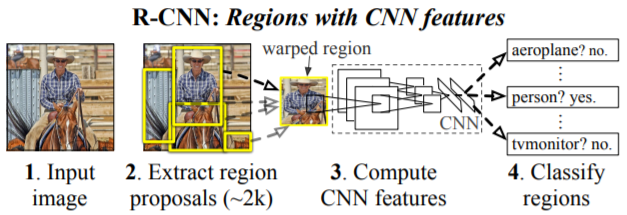
以上流程看起来并不复杂,但在阅读论文时仍产生不少疑问,这里按照R-CNN的算法流程,逐一列出自己的疑惑点,并根据查阅的相关博文资料对疑惑点进行解答(论文的附录里有相应解答)。
1. Selective Search如何生成Region Proposal ?
Selective Search是一种图像分割方法,基本思想如下:
- 使用一种过分割的手段,将图像分割成很多小区域;
- 按照某种合并规则来合并可能性最高的相邻两个区域,重复该步骤直到整张图像合并成一个区域位置;
- 输出所有曾存在过的区域,即为Region Proposal;
合并规则如下:
- 颜色相似度:合并颜色(颜色直方图)相近的
- 纹理相似度:合并纹理(梯度直方图)相近的
- 尺寸相似度:合并那些合并后总面积最小的,保证合并操作的尺度较为均匀,避免一个大区域陆续‘吃掉’其他小区域
- 填充相似度:合并那些合并后外包Bounding Box较小的
论文中给出的算法流程图如下:

2. Region Proposal resize到固定大小时如何操作 ?
所有候选区域的图像最终是要进入CNN网络进行特征提取,而使用Selective Search方法提取到的候选框的大小都是不一样的,CNN网络又需要固定的输入,所以需要对候选框图像进行一定的缩放,使它们达到相同的大小,假设目标大小为m*n(论文中227*227),文章中试验了以下两种不同的处理方法:
- 各向异性缩放:简单来说,就是强制图片缩放到
m*n,而不考虑它发生的形变(不考虑图像的原始长宽比例),如下图(D)所示:
- 各向同性缩放:在一定程度上减少图片变形,有两种方法:
- 先扩充后裁剪:直接在原始图片中,把bounding box的边界进行扩展延伸成正方形,然后再进行裁剪;如果已经延伸到了原始图片的外边界,那么就用bounding box中的颜色均值填充;如上图(B)所示;
- 先裁剪后扩充:先把bounding box图片裁剪出来,然后用bounding box的像素颜色均值填充成正方形,如上图(C)所示;
对于上述各向异性和各向同性缩放,文中还有一个padding处理,上面示意图中第1、3行是结合了padding=0,第2、4行是结合了padding=16的结果,经过试验,作者认为采用各向异性缩放、padding=16时效果最好。
要注意的一点是,经过resize之后的候选区域会输入到CNN网络中进行分类,若最终的分类结果表明该区域中包含某一类物体,那么原始候选区域(也即上图中的(A))就是网络预测的box,该box进一步经过Bounding-box Regression精调后形成最终预测的box。
3. 原则上CNN网络已经实现了对Region Proposal的分类,为什么还需要SVM ?
在R-CNN中,CNN网络结构仅仅作为特征提取器使用,原则上可以替换为任意的符合输入输出要求的网络结构,论文中作者使用AlexNet和VGGNet进行了测试。
这里要说的是,CNN网络首先在ImageNet的分类数据集上进行了预训练,然后舍弃最后一层的softmax层,此时通过网络的图片,在网络输出处获得的是一个4096维的特征向量。
在此之后,作者又使用从PASCAL VOC数据集或ILSVRC2013数据集中提取到的Region Proposal对网络进行精调。此时若Region Proposal与Truth box的IOU大于0.5则被认为是正样本,否则为负样本。作者使用32正样本+64负样本=128 mini batch的方法对网络进行精调,按照这种方法,对每一个Region Proposal,经过精调的CNN网络已经具备了对其分类的能力,而作者并没有直接使用该分类结果,而是使用分类层之前的4096维向量去训练一个SVM分类器,在测试时则是以该SVM分类器的结果作为最终的分类结果。
这里首先要注意在精调CNN网络时和训练SVM时对正负样本定义的不同: 在精调CNN网络时,一张图片上所有的Region Proposal与某一个ground-truth box计算IOU,凡是与该ground-truth box的IOU大于等于0.5的Region Proposal都被认为是该类别的正样本,其他的被认为是该类别的负样本; 在训练SVM时,作者只使用ground-truth box作为正样本,把与当前ground-truth box所在类别的所有ground-truth box的IOU都小于0.3的Region Proposal作为负样本进行训练,并忽略其他Region Proposal。
在Appendix B中,作者已经说明,最初是直接使用预训练模型的4096维向量训练SVM分类器,并没有使用精调步骤,之后才逐步改进到目前的步骤,可为什么不直接使用精调后CNN的分类结果,而是再训练一个SVM分类器?
作者曾这样试验过,发现精度下降较多,作者认为比较可能的原因是精调CNN分类器时所定义的正样本比较宽松,没有强调出box的位置,而微调CNN网络仅仅使用ground-truth box作为正样本时样本量又不够,相反训练SVM则不需要太多样本,所以才改进到目前这种状态,即预训练->精调->SVM分类。
4. Bounding-box Regression 如何训练和使用 ?
以P表示网络预测的box的参数,即中心坐标+宽和高,以G表示ground-truth box的参数,分别为x,y,w,h定义如下线性回归式,式中Φ5(P)指的是AlexNet的Pooling5池化层的参数:
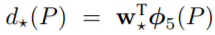
也即作者是使用相应的池化层参数对当前Region Proposal的位置进行回归,公式如下:
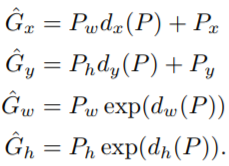
真实值与预测值的误差如下:
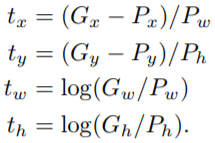
相应的Loss函数如下,通过对该方程进行优化,可找到一组合适的权值用于测试时的box参数回归计算:
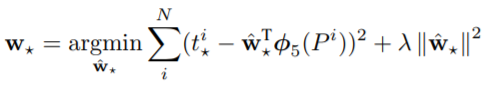
在上面的Loss函数中,作者为其添加了正则化项,通过实验表明,该项非常有效。另外作者发现,在训练时(P,G)对的选取也非常重要。
5. Other Tricks
Non-Maximum Suppression
在test阶段,算法可能对同一物体产生多个候选框,此时算法并非直接选取概率最大的框而舍弃掉其他框,而是采用NMS的策略逐步取舍。 假设对某一物体产生了6个候选框,概率从小到大依次为A B C D E F:
- 从最大概率候选框F开始,计算其他框与F的IOU是否大于某个阈值;
- 假设B D与F的IOU超过阈值,则丢掉B D,并保留F;
- 对剩下的A C E,重复上述操作,判断E与A C的IOU,并保留E;
- 重复上述操作,直到找到所有被保留下来的框;
6. Conclusion
R-CNN虽然在当时达到了较好的效果,但是整个的训练过程分为多个步骤,较为繁琐,且无论是训练和测试,速度都较慢,但它的思想值得借鉴。