0. Introduce
本篇Blog用于总结:
- Classification、Detection和Segmentation等任务的具体含义
- 不同任务或不同数据集的评估标准
- 基于深度学习的Classification、Detection等论文中常用的评估模型性能的指标
相关内容会随着自己的学习不断更新。
1. Task
Classification
Detection
Segmentation
2. Evaluation Criteria
图像分类性能评估指标
Top-1 & Top-5: 这两个标准主要用于ImageNet的分类任务中: Top-1 error rate:对一张图片,若概率最大的是正确答案,则认为分类正确,否则错误; Top-5 error rate:对一张图片,若概率前五的中包含正确答案,则认为分类正确,否则错误; 根据上述标准可得到Top-k的错误率,与之对应的是准确率(accuracy)。 由于ImageNet中的图像label有一定的误差,很多图片在人类看来可以归为好几类,所以一般将Top-5作为一个重要的评估标准。
机器学习性能评估指标
1. TP/TN/FP/FN
通过下图来解析TP/TN/FP/FN等概念:
如下图所示,左侧为正样本,右侧为负样本,而圆中的样本是模型预测为正类的样本,圆外是模型预测为负类的样本,则TP和TN都是指被正确分类的样本数量,FP指将负样本预测为正样本的数量,FN指将正样本预测为负样本的数量:
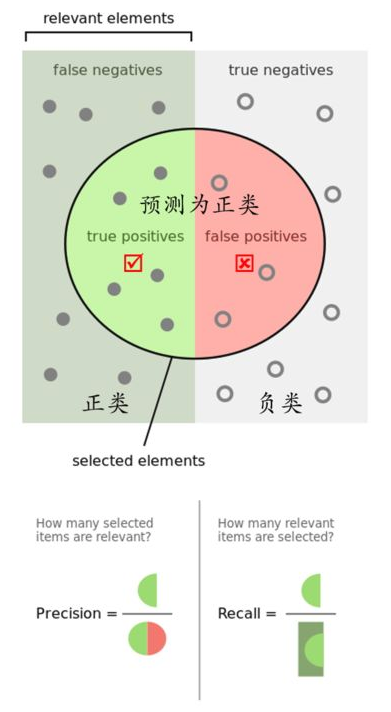
在这四个概念的基础上,又引出了精确率(precision)和召回率(recall),进而引出ROC和AUC两个概念,这里分别进行解释。
2. Precision/Recall/F1 首先区别准确率(accuracy)和精确率(Precision),可通过其定义进行理解: \(ACC=\frac{TP+TN}{TP+FP+TN+FN}\) \(P=\frac{TP}{TP+FP}\) 可以看出,准确率衡量了所有正确分类的样本(正类和负类)占总样本的比例,而精确率仅衡量了正确分类的正样本占所有分类为正样本的比例。 当正负样本不平衡时,准确率指标会失效。如当正样本远多于负样本时,若我们将所有样本都预测为正样本,依然会有比较好的结果。
召回率(Recall)的定义为: \(R=\frac{TP}{TP+FN}\) 可以看出,召回率衡量了正确分类的正样本占所有正样本的比例。
从精确率和召回率的分母不同可以看出:
- 精确率是针对预测结果而言的,它表示预测为正类的样本中有多少是对的;
- 召回率是针对原始样本而言的,它表示样本中的正类有多少被预测对了;
在信息检索领域,精确率和召回率又被称为查准率和查全率,可结合上面的分析去理解这两个概念。
查准率和查全率是一对相互矛盾的概念,一般当一个量较高时,另一个往往较低,通过调整阈值可得到一系列的查准率和查全率的值,可将模型的预测结果按照confidence由高到低进行排序,然后对每个样本(注意此处不是confidence)分别作为阈值来计算查准率和查全率,进而可绘制出相应的P-R曲线,如下图所示:
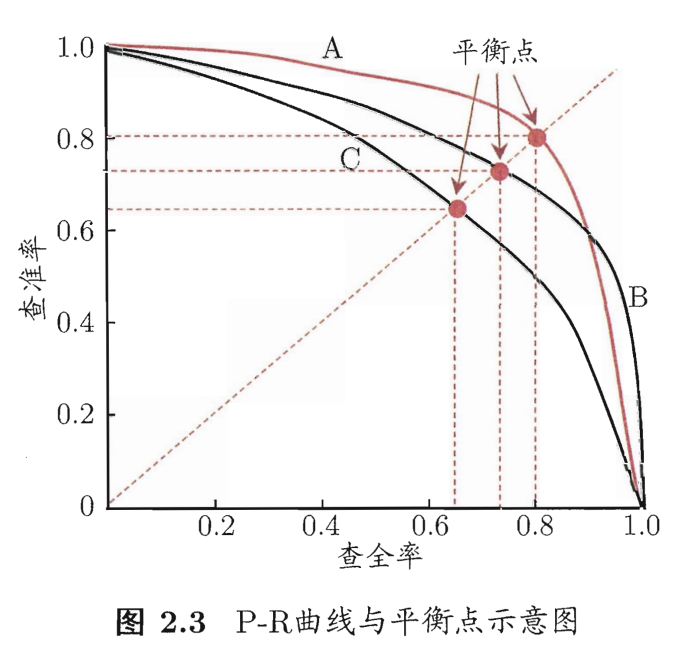
上图中共有三条曲线:
- A和B曲线分别包住C,说明A和B的性能优于C;
- A和B发生了交叉,若要比较其性能,一般在具体的查准率或查全率下比较,或者综合查准率和查全率进行比较:
- 平衡点(Break-Event Point): 查准率=查全率时的值,如图中所示,可认为A优于B,但该标准过于简单,不常用;
- $F_1$值: 查准率和查全率的调和均值,在二者都很高的情况下,$F_1$值也很高:\(\frac{2}{F_1}=\frac{1}{P}+\frac{1}{R}\) \(F_1 = \frac{2TP}{2TP+FP+FN}\)
3. ROC/AUC 在介绍ROC曲线之前,需要引入另外两个概念:真正率和假正率。 真正率描述的是正确分类的正样本占所有正样本的比例,也即是召回率: \(true\space positive\space rate: TPR=\frac{TP}{TP+FN}\) 假正率描述的是错分为正样本的负样本占所有负样本的比例: \(false\space positive\space rate: FPR=\frac{FP}{FP+TN}\)
ROC曲线则根据上述两个概念绘制而成(阈值的选取与P-R曲线相同,根据对样本预测的confidence),分析可知,当曲线越靠近左上角,分类器性能越好:
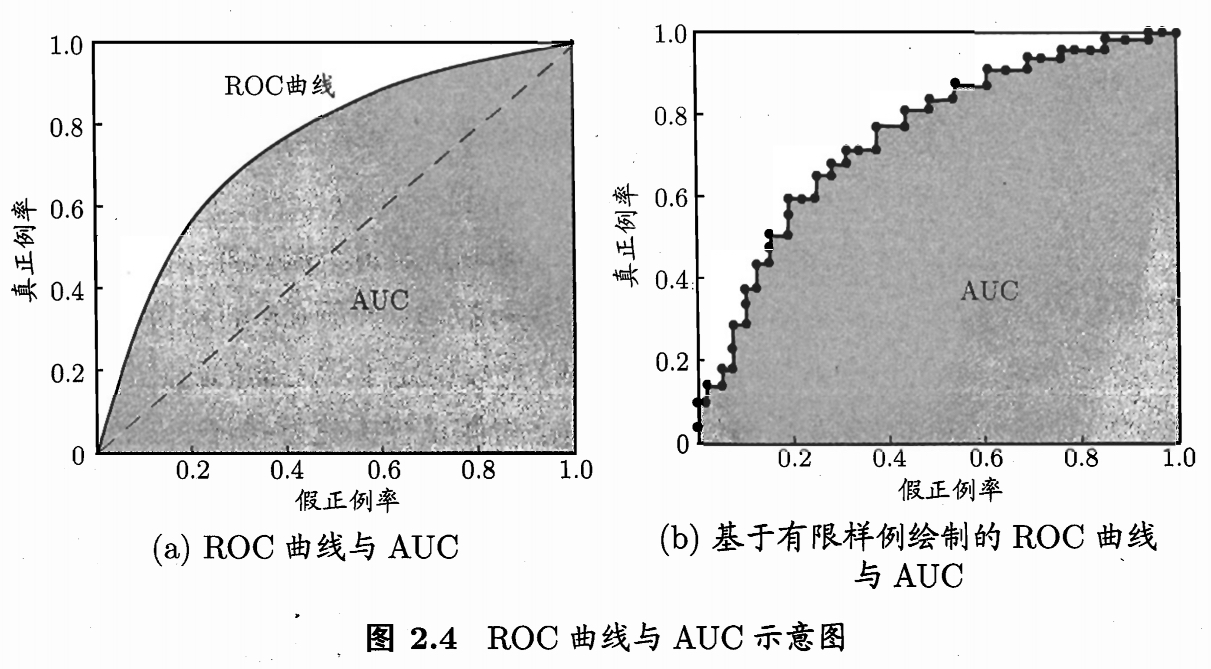
AUC(Area Under Curve)被定义为ROC曲线下的面积,该面积值不会大于1,简单地说,AUC值越大的分类器,正确率越高:
- AUC = 1: 完美的分类器,无论设定什么阈值,都能正确分类;
- 0.5<AUC<1:优于随机猜测,若给分类器设定合适阈值,有预测价值;
- AUC=0.5:预测结果与随机猜测一样,模型没有预测价值;
- AUC<0.5:不可该比随机猜测还差,所以不存在这种情况。
在样本中正负样本不均衡时,ROC和AUC能给出较好的评估结果。
目标检测性能评估指标
1. IoU
Intersecton over Union
目标检测任务中,物体通常使用一个框标出,在模型给出预测时,同样也是给出一个框,IoU就是用来衡量预测框与真实框之间重合度的指标,如下图所示:
 \(IoU=\frac{Area\space of\space Overlap}{Area\space of\space Union}\)
\(IoU=\frac{Area\space of\space Overlap}{Area\space of\space Union}\)
通常认为IoU>0.5就是一个比较好的结果。
另外,框的位置通常有两种表示方法:
- 使用左上角和右下角两个坐标表示;
- 使用中心坐标和长宽表示;
2. mAP - PASCAL VOC
mean Average Precision
mAP: 各个类别AP的平均值
AP: P-R曲线下的面积
由前面的内容可以知道(前面是以二分类问题为例),P-R曲线是针对某一类别的分类结果所绘制出的曲线。
因此,要计算mAP,首先要绘制出每一类的P-R曲线,然后计算出各个类别的AP,最后求平均得到mAP。
对于如何计算AP,PASCAL VOC使用过两种不同的方法:
- 在VOC2010以前,仅选取Recall >= 0, 0.1, 0.2, …, 1共11个点时的Precision的最大值,AP为这11个Precision的平均值;
- 在VOC2010及以后,需要对每一个不同的Recall值(包括0和1),选取大于等于当前Recall值时的Precision的最大值,用该Precision作为高,当前Recall区间作为宽形成的矩形来近似当前曲线下的面积,所有小区间的和即为AP值;
需要注意的一点是,在PASCAL VOC中,只要Ground Truth Box与Predict Box的IoU大于0.5,就认为该Ground Truth Box被找到,相应Predict Box为正类,否则Predict Box为负类。
下面给出一个计算示例:
设对于Aeroplane类别,网络有以下输出(BB表示Bounding Box的缩写,且Predict Box已经与GT计算IoU确定了正负类):
BB | confidence | GT
----------------------
BB1 | 0.9 | 1
----------------------
BB2 | 0.9 | 1
----------------------
BB1 | 0.8 | 1
----------------------
BB3 | 0.7 | 0
----------------------
BB4 | 0.7 | 0
----------------------
BB5 | 0.7 | 1
----------------------
BB6 | 0.7 | 0
----------------------
BB7 | 0.7 | 0
----------------------
BB8 | 0.7 | 1
----------------------
BB9 | 0.7 | 1
----------------------
由上可以看出,TP=5(BB1, BB2, BB5, BB8, BB9),FP=5(重复检测到的BB1算是FP)。 假设除了已经检测到的5个GT以外,还有两个GT没有被检测到,即FN=2。 此时可以按照Confidence的顺序给出各处的PR值,并绘制出曲线,如下:
rank=1 precision=1.00 and recall=0.14
----------
rank=2 precision=1.00 and recall=0.29
----------
rank=3 precision=0.66 and recall=0.29
----------
rank=4 precision=0.50 and recall=0.29
----------
rank=5 precision=0.40 and recall=0.29
----------
rank=6 precision=0.50 and recall=0.43
----------
rank=7 precision=0.43 and recall=0.43
----------
rank=8 precision=0.38 and recall=0.43
----------
rank=9 precision=0.44 and recall=0.57
----------
rank=10 precision=0.50 and recall=0.71
----------
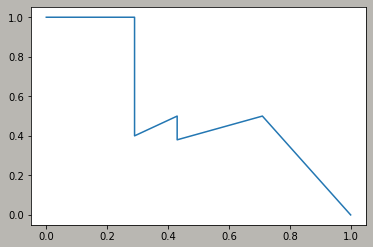
以rank=5的计算为例,此时以BB4作为分界点,confidence=0.7, TP=2, FP=3(BB4之前都被预测为正类,之后被预测为负类), TN=3, FN=5, precision=2/(2+3)=0.40, recall=2/(2+5)=0.29。
对上述PR值,可采用前述两种不同的方法计算AP:
-
VOC2010之前的方法,我们选取Recall >= 0, 0.1, …, 1的11处Percision的最大值:1, 1, 1, 0.5, 0.5, 0.5, 0.5, 0.5, 0, 0, 0。此时Aeroplane类别的 AP = 5.5 / 11 = 0.5
-
VOC2010及以后的方法,对于Recall >= 0, 0.14, 0.29, 0.43, 0.57, 0.71, 1,我们选取此时Percision的最大值:1, 1, 1, 0.5, 0.5, 0.5, 0。此时Aeroplane类别的 AP = (0.14-0)1 + (0.29-0.14)1 + (0.43-0.29)0.5 + (0.57-0.43)0.5 + (0.71-0.57)0.5 + (1-0.71)0 = 0.5
按照上述方法计算每个类别的AP,再计算均值就为mAP。
3. AP - MS COCO MS COCO数据集的评估标准比PASCAL VOC严格许多,PASCAL VOC中,IoU>0.5即认为是正样本,但在COCO中,IoU阈值在[0.5, 0.95]区间内每隔0.05取一次值,这样即可算出10个类似于PASCAL VOC的mAP,这10个值再做平均,即为最后的AP值。
下图总结了COCO数据集的评估标准:
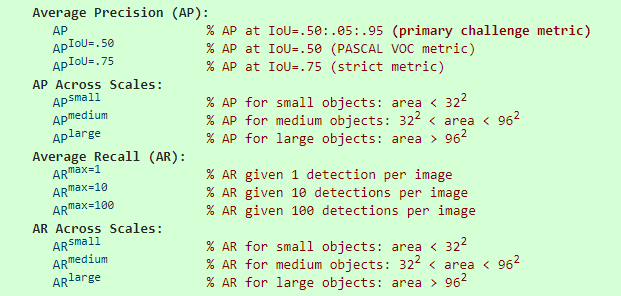
除去AP外,COCO数据集还针对三种不同大小(small, medium, large)的图片提出了评估标准。 在COCO中,约41%的小目标(area<32x32),34%的中等目标(32x32<area<96x96),24%的大目标(area>96x96),针对这些目标分别计算AP也可以反映出模型的性能。
图中还有一个AR的指标用以计算模型的召回率,这些指标都可以通过COCO提供的API来完成计算:https://github.com/cocodataset/cocoapi
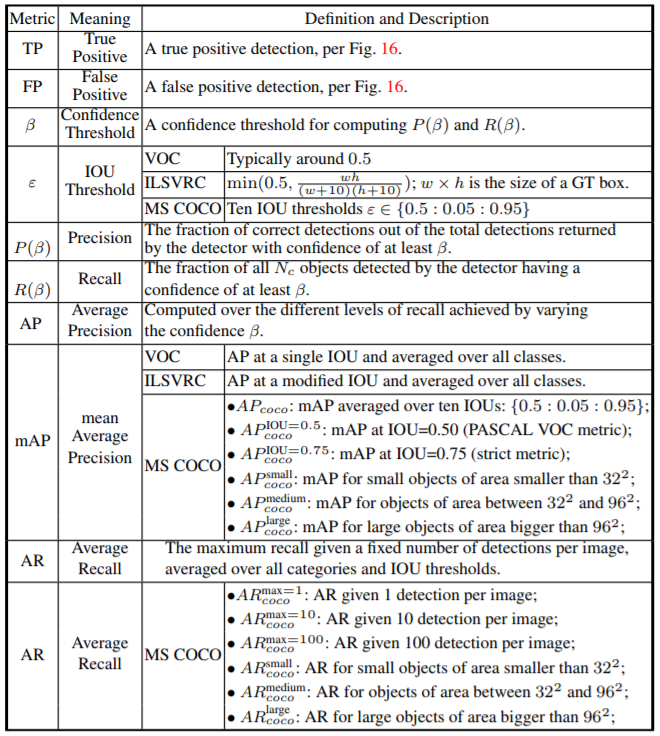
下图是比较详细的各种评测标准的总结:
3. Model Performance Criteria
FLOPs
FLOPs: Floating point operations,即浮点运算量,包括浮点数的乘法和加法运算。 (区别于FLOPS:floating point operations per second,每秒浮点运算次数,是一个衡量硬件性能的指标)
对于CNN模型,FLOPs的计算量主要来自于Conv操作,其次是FC/BN/ReLU/Pooling等。
Paper中较常用的单位为GFLOPs:10亿次浮点运算(1 GFLOPs = 10^9 FLOPs)。
下面总结Conv层和FN层的FLOPs的计算方法(不考虑activation function)的运算:
Conv层:$FLOPs = (2C_{in}K^2-1)HW*C_{out}$
FC层:$FLOPs = (2In-1)Out$
Parameters
FPS
这个参数与机器性能有很大关系,所以比较起来感觉并没有什么意义。
Reference
[《机器学习》周志华] Recall & precision et al mAP FLOPs and Parameters Object Detection Survey