0. Introduce
本篇Blog用于总结:
- 在Image Classification、Object Detection及Object Segmentation等视觉任务中常用的数据集
- 机器学习、深度学习方向的竞赛
- 计算机视觉、深度学习等方向的会议
- AI相关的学习资料
相关内容会随着自己的学习不断更新。
1. Dataset
MNIST
CIFAR
ImageNet
PASCAL VOC
PASCAL: Pattern Analysis, Statical Modeling Computational Learning
PASCAL VOC: The PASCAL Visual Object Classes
1. PASCAL VOC挑战赛简介 PASCAL VOC挑战赛是一项世界级的计算机视觉挑战赛,举办时间为2005-2012,比赛项目包括分类、检测、分割、人体布局、动作识别等,该挑战赛催生了大批优秀的计算机视觉模型,尤其是以深度学习为主的模型,如R-CNN系列、YOLO、SSD等。该比赛目前虽已停办,但PASCAL VOC数据集仍被众多研究者作为比较模型性能的一个标准,PASCAL VOC官方也持续开放其服务器来为研究者评估模型性能。
2. PASCAL VOC数据集简介
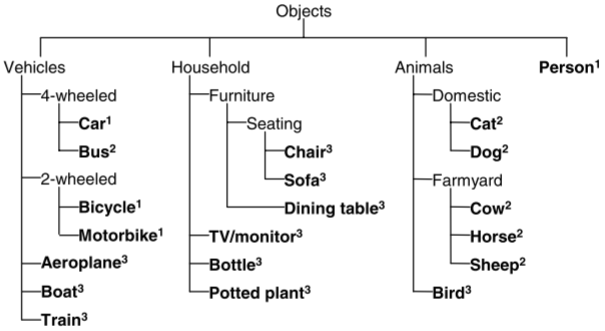
从2007年开始,PASCAL VOC数据集按下图结构进行组织,总计四大类20小类:
PASCAL VOC数据集的发展历程可参考官网的summary,这里简述如下:
-
从2005年至2007年,数据集由4类1578张图片增加到20类9963张图片,这几年的比赛,test集的标注信息也会公开发布,从2008年开始不再发布;
-
从2005年至2008年,虽然每年的数据集数量都在增加(2008年少于2007年),但这些数据集都是互斥的,相互之间不包含;
-
从2009年开始,每年的数据集是在前一年数据集的基础上进行扩充,如2009包含2008,以此类推;
-
每年数据集的划分情况为: trainval:test约为1:1,其中train:val约为1:1,每张图片中可能有多个标注物体;
-
2012年的数据量: train/val:11540张图片和27450个标注物体;
-
以上描述主要针对分类和检测任务,分割任务的数据集是上述数据集的一个子集;
3. 常用的PASCAL VOC数据集 研究者目前较常用的PASCAL VOC数据集的年份为2007年和2012年,因为二者互不包含,且2012包含了从2008开始的数据集,常用方法如下:
- VOC2007的trainval训练,VOC2007的test测试;
- VOC2012的trainval训练,VOC2012的test测试;
- 07+12:VOC2007和VOC2012的trainval训练,VOC2007的test测试;
- 07++12:VOC2007的trainval+test和VOC2012的trainval训练,VOC2012的test测试;
- 07+12+COCO:先在MS COCO上预训练,再使用07+12进行微调和测试;
- 07++12+COCO:先在MS COCO上预训练,再使用07++12进行微调和测试;
以下两篇论文分别总结了PASCAL VOC2007和2012的数据集情况,及一些模型及其性能对比: PASCAL VOC 2007 PASCAL VOC 2012
4. PASCAL VOC2007&2012数据集简介
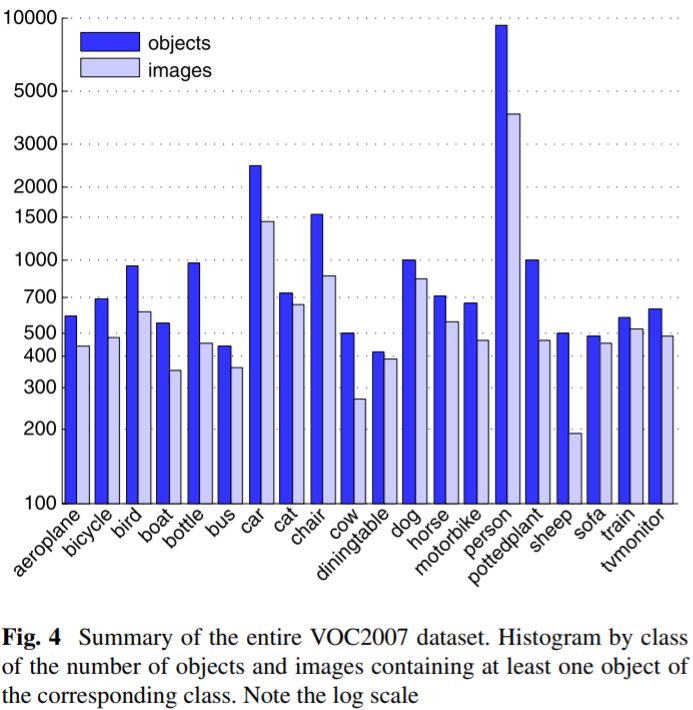
PASCAL VOC2007数据集每个类别所包含的图片数量和物体数量如下图所示(注意坐标轴的尺度),若按四大类进行统计,四个类别所包含的图像数量基本均衡:
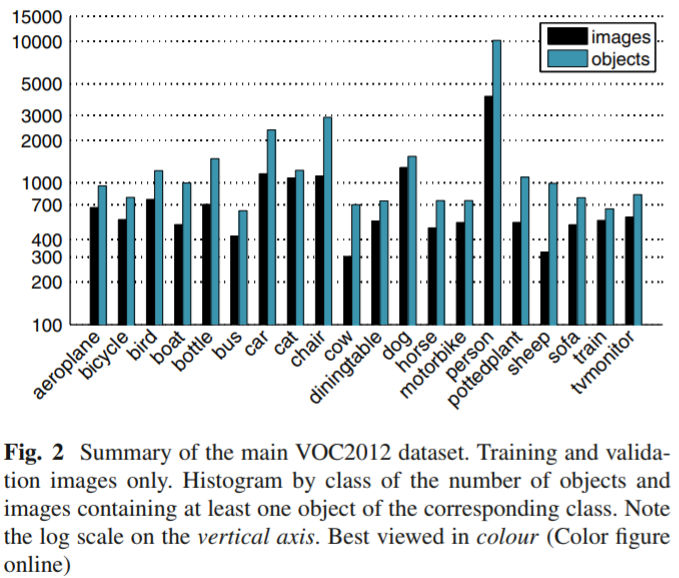
PASCAL VOC2012数据集的总体情况如下图所示:
VOC2007和VOC2012数据集对比如下图,黑色字体数据为官方数据,红色字体数据为根据数据集划分比例的推测数据:

5. PASCAL VOC数据集文件组织方式 以VOC2007为例,说明文件的组织方式:
.
├── Annotations 进行detection任务时的标签文件,xml文件形式
├── ImageSets 存放数据集的分割文件,比如train,val,test
├── JPEGImages 存放 .jpg格式的图片文件
├── SegmentationClass 存放按照class 分割的图片
└── SegmentationObject 存放按照 object 分割的图片
-
在PASCAL VOC数据集中,每张图片都有一个唯一的ID编号,由6位整数构成,不同文件夹通过该ID来进行图片和标注信息的对应;
-
对Annotations,每个标注框的坐标信息格式为:
<left> <top> <right> <bottom>; -
对ImageSets,包含三个子文件夹 Layout,Main,Segmentation,其中Main文件夹用于分类和检测任务,Layout文件夹存放用于人体布局任务,Segmentation用于分割任务;
-
Main文件夹中按类别的分割文件主要用于分类任务,文件中指定出了文件名及正负样本,以
airoplane_train.txt为例,示例如下,前一列与train.txt内容相同,后一列标明正负样本:000032 1 000033 1 000042 -1 …… …… 009949 -1 009959 -1 009961 -1
6. PASCAL VOC挑战赛提交格式 下面简述分类和检测任务中提交到PASCAL VOC服务器上的格式: 对每一个物体类别,都有一个单独的txt文件,该txt文件仅包含被分类到当前类别的图像:
- 对Classification Task:第一列表示图片名称,第二列表示预测分数:
<image identifier> <confidence>; - 对Detection Task:每行存储一个box的信息,格式如下:
<image identifier> <confidence> <left> <top> <right> <bottom>。
MS COCO
MS COCO: MicroSoft Common Objects in Context
MS COCO是微软构建的一个数据集,COCO竞赛主要包括检测/分割/关键点检测等任务。 相比于PASCAL VOC数据集,COCO数据集包含了总计80个类别,图片主要来源于生活场景,背景较为复杂,同一张图片上目标数量较多(平均每张图片包含3.5个类别和7.7个实例目标,VOC中1.4和2.3个, ImageNet中1.7和3.0个),目标尺寸较小,因此任务难度更大。因此MS COCO数据集是除PASCAL VOC外衡量模型性能的一个重要标准(对检测任务)。
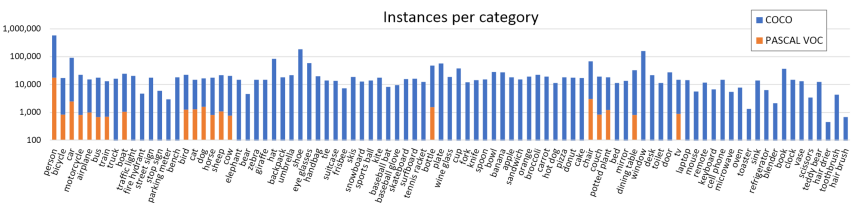
MS COCO与PASCAL VOC的对比如下图,可以看出,MS COCO在类别数量上和每个类别的图像数量上都比PASCAL VOC要多:
目前MS COCO网站上提供2014/2015/2017三个年份的数据集下载,分别说明如下:
-
2014: train:83k val:41k test:41k
2:1:1 -
2015: 官网只给出了2015的test集,所以2015比赛的训练集用的还是2014年的?
-
2017: 图片和detection/keypoints的标注信息都没变,只是将将train和val的数据划分调整为118k/5k
论文中还有一个比较常用的划分是将COCO2014的验证集划分为两份,在trainval35k上进行训练(可能包括原有的train数据集),在minival上进行测试,具体的信息可以从这里看到。这种划分的最终结果与COCO2017的划分类似。
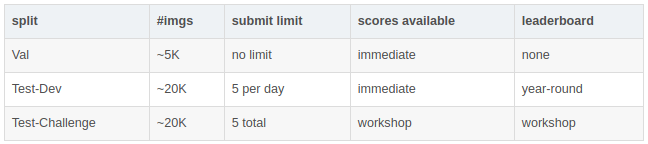
关于测试集,在2017年,测试集由四个拆分:dev/standard/reserve/challenge,从2017年开始,简化为只有dev/challenge拆分,具体如下图所示,二者的区别可以理解为提交次数的不同,具体可参考官网的Test Guidelines:
MS COCO不仅在规模上比PASCAL VOC要大,在模型的评估标准上也比PASCAL VOC要严格,这部分总结在下一篇Blog中。
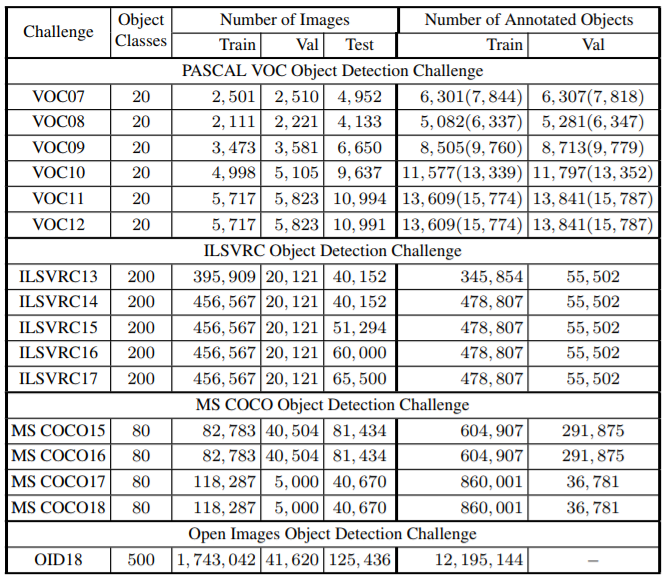
下图是比较详细的数据集对比:
2. Competitation
Kaggle
天池
DF
3. Conference
AAAI
[NIPS]
[CVPR]
[ICCV]
[ICML]
[IJCAI]
[ECCV]
[ICLR]
[arXivs]
4. Driving Force
Reference
PASCAL VOC 1 PASCAL VOC 2 MS COCO 1 MS COCO 2 Object Detection Survey