本篇文章观点仅限于目前的理解,后续若有新的理解,还会继续更新。
Introduce
ShuffleNet v1是2018年CVPR上的一篇论文中提出的,作者团队为Face++(旷视科技),它提出于MobileNet v1之后,它的目的与MobileNet类似,主要是想降低计算量,便于将网络部署到计算能力有限的终端设备上。
Google对从2015年开始提出的Inception网络不断优化,在2017年提出的Xception网络引入了Depth-wise Separable Convolution,将卷积分为Depth-wise Convolution和Point-wise Convolution两个步骤大大降低了参数量和计算量;Facebook提出的ResNeXt网络则是对ResNet改进(残差网络的三篇论文都有He参与,只是分别在微软和Facebook),提出了Group Convolution,即首先使用Point-wise Convolution进行降维,再对channel分组以进行Gropu Convolution,最后再使用Point-wise Convolution升维至所需维度,这种方法同样可以减少参数量和计算量,并且这种两端大(channel多)中间小(channel少)的设计通常被称为bottleneck,目前这种设计已经被证明能够较好提取图像特征。
以上提到的网络结构都是通过Sparse Connection的方法来降低运算量并提高卷积运算的效率(个人对Sparse Connection的理解是: 卷积核越小,通道数越少,下一层某个神经元与前一层的连接就越少),所以在ShuffleNet的设计上,作者同样采用了这一理念。
通过对Xception和ResNeXt进行分析,作者发现Depth-wise Convolution和Gropu Convolution中使用的Point-wise Convolution占用了大量的模型运算量,如在ResNeXt中占用达到93.4%。因此作者在此基础上提出了一种新颖的ShuffleNet模块,具体分析如下。
Channel Shuffle for Group Convolutions
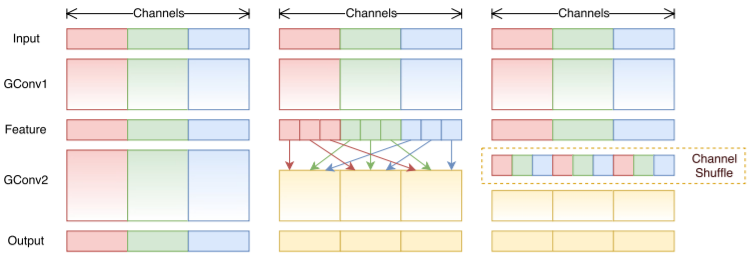
由于RexNeXt网络中1*1卷积占用的计算较多,并且分组卷积又可降低计算量,所以作者考虑不使用1*1卷积而直接进行多个分组卷积层的叠加,如下图左侧示意图所示,但这样会带来一个问题,即不同组之间的信息无法交流,所以作者提出了Channel Shuffle操作,在一个分组卷积层后对不同组的特征进行重排后再送入下一组,如图所示:
ShuffleNet Unit
Channel Shuffle操作理论上实现了不需要1*1卷积进行降维和升维的分组卷积操作,理论上可以构建较为强大的模型,作者在此基础上又进一步探索,设计出了结合Gropu Convolution、Depth-wise Convolution和残差结构的ShuffleNet Unit。
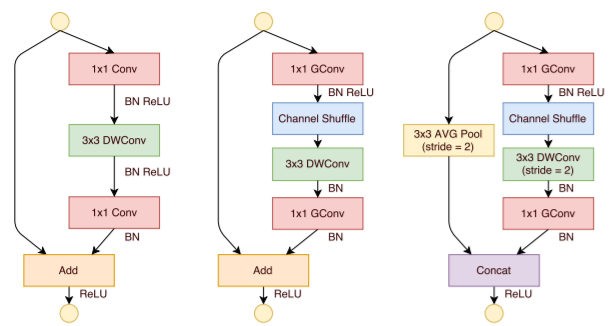
如下图左侧示意图所示,这是一个带有残差连接的bottleneck单元,其中的3*3卷积改为了Depth-wise Convolution,bottleneck单元和残差结构都已被证明在CNN网络中比较有效,而这里使用Depth-wise Convolution又降低了参数数量,但正如最开始分析的那样,1*1的卷积给网络带来了巨大的计算量,所以作者考虑将1*1的卷积设计为Gropu Convolution+Channel Shuffle,如下图中间示意图所示,对1*1的卷积引入Gropu Convolution又可大大降低计算复杂度,该单元就是最终的ShuffleNet Unit。下图中右侧示意图表示的是特征图体积减半的ShuffleNet Unit结构:
Network Architecture
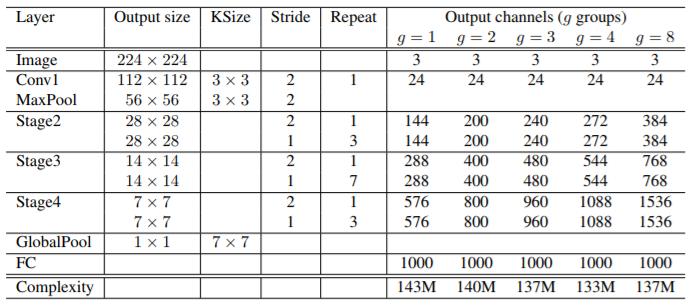
最终的网络结构如下表所示,参数g控制分组数量,进而控制网络复杂度:
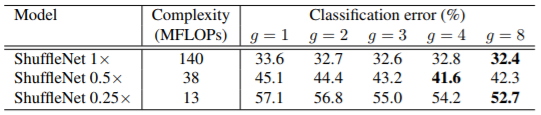
下图对比了不同的ShuffleNet模型的复杂度以及分类精度,其中参数s是一个应用于channel的尺度缩放系数,与MobileNet v1中的类似:
作者还做了一系列的对比实验来说明该结构的有效性,这里不再赘述。
Convolution
ShuffleNet v1结合了Gropu Convolution、Depth-wise Convolution和残差结构的设计方法,大大降低了网络参数量和计算复杂度,是目前压缩性能较好的网络之一。