Introduce
本文记录对AlexNet复现的流程及过程中遇到的一些问题,AlexNet网络结构使用tf.keras编写,并加载预训练权重,最终在ILSVRC-2012的验证集上做最终测试,每张图仅使用1-Crop,得到的Top-1和Top-5错误率分别为48.0%和24.1%,作者论文中使用5-Crop在该数据集上的测试结果为40.7%和18.2%。 程序源码及结果在这里。
AlexNet Architecture
本文中实现的网络结构和预训练权重都来自于tornoto大学相应的网站,不同的是,该站点中给出的网络结构是使用TensorFlow进行构建的,这里改用了tf.Keras,代码如下:
def conv2d_bn(x, filters, kernel_size, strides, pad, name, activation='linear', group=1):
# group = 1 or 2
if group==1:
x = Conv2D(filters, kernel_size, padding=pad, strides=strides, activation=activation, name=name)(x)
else:
x_a, x_b = Lambda(lambda x: tf.split(x, group, axis=-1))(x)
x_a = Conv2D(filters//2, kernel_size, padding=pad, strides=strides, activation=activation, name=name+'a')(x_a)
x_b = Conv2D(filters//2, kernel_size, padding=pad, strides=strides, activation=activation, name=name+'b')(x_b)
x = concatenate([x_a, x_b])
return x
def AlexNet(img_shape=(227, 227, 3), num_classes=1000, weights='bvlc_alexnet.npy'):
input = Input(img_shape)
conv1 = conv2d_bn(x=input, filters=96, kernel_size=11, strides=4, pad='SAME', group=1, name='conv1')
# conv1 = BatchNormalization()(conv1)
conv1 = ReLU()(conv1)
conv1 = Lambda(lambda x: tf.nn.local_response_normalization(x, depth_radius=2, alpha=2e-05, beta=0.75, bias=1.0))(conv1)
pool1 = MaxPooling2D(pool_size=3, strides=2)(conv1)
conv2 = conv2d_bn(x=pool1, filters=256, kernel_size=5, strides=1, pad='SAME', group=2, name='conv2')
conv2 = ReLU()(conv2)
conv2 = Lambda(lambda x: tf.nn.local_response_normalization(conv2, depth_radius=2, alpha=2e-05, beta=0.75, bias=1.0))(conv2)
# conv2 = BatchNormalization()(conv2)
pool2 = MaxPooling2D(pool_size=3, strides=2)(conv2)
conv3 = conv2d_bn(x=pool2, filters=384, kernel_size=3, strides=1, pad='SAME', activation='relu', group=1, name='conv3')
conv4 = conv2d_bn(x=conv3, filters=384, kernel_size=3, strides=1, pad='SAME', activation='relu', group=2, name='conv4')
conv5 = conv2d_bn(x=conv4, filters=256, kernel_size=3, strides=1, pad='SAME', activation='relu', group=2, name='conv5')
pool5 = MaxPooling2D(pool_size=3, strides=2)(conv5)
flatten5 = Flatten()(pool5)
fc6 = Dense(4096, activation='relu', name='fc6')(flatten5)
# drop6 = Dropout(0.5)(fc6)
fc7 = Dense(4096, activation='relu', name='fc7')(fc6)
# drop7 = Dropout(0.5)(fc7)
fc8 = Dense(num_classes, activation='softmax', name='fc8')(fc7)
model = Model(input, fc8)
这里要注意以下几点:
-
输入图片大小应为
227*227*3,通道顺序为BGR,论文中的224*224*3貌似有误; -
AlexNet是最早使用Group Convolution的网络,这里在使用tf.Keras构造Group Convolution时,使用了TensorFlow的
tf.split()函数,由于TensorFlow构造的是静态图模型(tf.split()返回的只是一个op),而tf.Keras构造的是动态图模型(返回的是运行后的tensor),所以要将tf.split()使用Keras的Lambda函数包装一下,以直接获得运算结果(或者说,只要是在Keras中使用tf中的操作,都需要包装一下); -
AlexNet中使用的LRN操作现在基本已经被更好用的BN代替,但是由于预训练权重是在LRN操作的基础上进行训练的,这里换成BN后使用预训练权重效果会差很多,所以要使用BN,还需要对网络重新训练;
-
AlexNet中使用了Dropout操作以防止训练过程中过拟合,但Dropout操作在测试时不应该再使用,Keras在测试阶段会自动停用掉Dropout层,所以这里写不写Dropout层都可以。(在AlexNet论文中,测试阶段时,每个神经元的输出乘以0.5,目的是将多个模型的输出取平均?)
Load Pre-trained Weights
预训练权重是.npy格式的文件,在搭建好网络后可根据每一层的名字把权重加载进去,代码如下:
weights_dic = np.load('bvlc_alexnet.npy', encoding='bytes').item()
# model.set_weights(weights_dic)
conv1w = weights_dic["conv1"][0]
conv1b = weights_dic["conv1"][1]
model.get_layer('conv1').set_weights([conv1w, conv1b])
conv2w = weights_dic["conv2"][0]
conv2b = weights_dic["conv2"][1]
w_a, w_b = np.split(conv2w, 2, axis=-1)
b_a, b_b = np.split(conv2b, 2, axis=-1)
model.get_layer('conv2a').set_weights([w_a, b_a])
model.get_layer('conv2b').set_weights([w_b, b_b])
conv3w = weights_dic["conv3"][0]
conv3b = weights_dic["conv3"][1]
model.get_layer('conv3').set_weights([conv3w, conv3b])
conv4w = weights_dic["conv4"][0]
conv4b = weights_dic["conv4"][1]
w_a, w_b = np.split(conv4w, 2, axis=-1)
b_a, b_b = np.split(conv4b, 2, axis=-1)
model.get_layer('conv4a').set_weights([w_a, b_a])
model.get_layer('conv4b').set_weights([w_b, b_b])
conv5w = weights_dic["conv5"][0]
conv5b = weights_dic["conv5"][1]
w_a, w_b = np.split(conv5w, 2, axis=-1)
b_a, b_b = np.split(conv5b, 2, axis=-1)
model.get_layer('conv5a').set_weights([w_a, b_a])
model.get_layer('conv5b').set_weights([w_b, b_b])
fc6w = weights_dic['fc6'][0]
fc6b = weights_dic['fc6'][1]
model.get_layer('fc6').set_weights([fc6w, fc6b])
fc7w = weights_dic['fc7'][0]
fc7b = weights_dic['fc7'][1]
model.get_layer('fc7').set_weights([fc7w, fc7b])
fc8w = weights_dic['fc8'][0]
fc8b = weights_dic['fc8'][1]
model.get_layer('fc8').set_weights([fc8w, fc8b])
由于搭建好的网络参数数量和权重文件的参数数量一致,所以考虑直接使用 model.set_weights()一次设定所有权重,但程序报错且未找到解决办法,这里根据层的名字逐层进行加载。
Preprocess ILSVRC-2012 Dataset
对ILSVRC-2012验证集进行预处理,主要是按图像最短边将其缩放至256,并取正中间的227*227*3作为测试用Crop。在论文中,作者这里取了四个角及中间一共5个Crop分别送入网络进行测试,5个Crop的测试结果的平均值作为最终结果。这里仅使用一个Crop。
在AlexNet中对图像使用的预处理方式仅仅是减去均值,通道顺序调整为BGR。
由于之前没有实际使用过ILSVRC数据集,所以下面详细总结一下ILSVRC数据集的Label和Keras网络预测的Label对应的问题。
ImageNet中的图片是以按照一种语义网络(WordNet)的方式组织的,可以把WordNet理解为一种层次结构,每一种物体根据语义的大小可以被分为不同的类别(个人理解:人既可以被分为人,也可以被分为哺乳动物,而哺乳动物的语义相对大一些),大的语义节点包含一些小的语义节点。
在ILSVRC-2012中,共使用了1000类物体,这1000类物体类别使用整数1-1000表示。严格地说,应该是1000类synsets(sets of synonymous nouns,近义词名词集合,如钱包在ILSVRC中被视为一类,但该类别相近的名词可以为wallet, billfold, notecase, pocketbook),这1000类synsets相当于是ImageNet的一个子集,每类synset都是ImageNet中的一个低级节点,且这些类别之间没有交集,并且没有语义包含关系。
ILSVRC竞赛中,每个synsets的信息都被存储在synsets数组中,这些数组被打包为meta.mat文件,可使用scipy读取该文件,返回一个字典,代码示例如下,字典中最的synsets键对应的就是所需的类别信息:
meta = scipy.io.loadmat('data/meta.mat')
meta.keys()
output:
dict_keys(['__header__', '__version__', '__globals__', 'synsets'])
打印第0个synset,信息如下,返回的是一个1*1的list,该list是由8个array组成的truple,每个array的含义由meta['synsets'][0]的dtype信息标识:
meta['synsets'][0]
output:
array([(array([[1]], dtype=uint8),
array(['n02119789'], dtype='<U9'),
array(['kit fox, Vulpes macrotis'], dtype='<U24'),
array([ 'small grey fox of southwestern United States; may be a subspecies of Vulpes velox'], dtype='<U81'),
array([[0]], dtype=uint8),
array([], shape=(1, 0), dtype=uint8),
array([[0]], dtype=uint8),
array([[1300]], dtype=uint16))],
dtype=[('ILSVRC2012_ID', 'O'),
('WNID', 'O'),
('words', 'O'),
('gloss', 'O'),
('num_children', 'O'),
('children', 'O'),
('wordnet_height', 'O'),
('num_train_images', 'O')])
下面对8个array的具体含义进行解释:
ILSVRC2012_ID : 当前synset在1000类中所对应的ID,如meta['synsets'][0]对应为1
WNID : 当前synset在WordNet整个语意网络中对应的ID,对某个synset,该ID恒定且唯一
words : 当前synset所对应的类别名称(近义词集合)
gloss : 对当前synset物体类别的简单描述
num_children : 在这个1000类的子集中,当前synset所包含的子节点的个数,应当为0
children : 当前synset所包含的子节点的ILSVRC1012_ID
wordnet_height : 在整个WordNet语意网络中,当前节点到达叶节点的最长路径,由于这1000类synset已经是叶节点,所以为0
num_train_images : 当前synset的训练集图像的个数
以上叙述主要注意两个ID:ILSVRC2012_ID和WNID,上例中分别为1和n02119789,其中WNID是一直跟随相应的synset的,而ILSVRC2012_ID则是根据此次比赛人为设定的。
在Keras中,网络最终会输出一个1000维向量作为预测结果,但需要注意的是,Keras网络输出的预测结果与ILSVRC2012_ID并不对应,比如预测向量的第一个元素Keras_ID=1(暂且认为该向量索引为1-1000)对应的并不是ILSVRC2012_ID=1或WNID=n02119789的synset。
事实上,Keras网络最终输出的1000维向量所对应的物体类别顺序与synset_words.txt文件中的顺序一致,比如Keras_ID=1对应的是该文件中的第一行WNID=n01440764,而ILSVRC2012_ID=1或WNID=n02119789在synset_words.txt中对应的是Keras_ID=279。
综上,对meta.mat文件进行预处理时,需要通过WIND将ILSVRC2012_ID映射到Keras_ID,具体代码可参考这里,清楚了上述过程后,这部分代码就不难理解。
227×227 or 224×224

-
根据上述公式计算AlexNet的Conv1的输出shape(
k=11, p=0, s=4, n_out=55),可以推出,输入的shape一定为227×227; -
这里在复现时使用的预训练权重及网络结构是由tornoto大学相应的网站提供的,它对AlexNet的Conv1的配置为
k=11, p=1, s=4,这也导致了后面各层输出shape的变化,与论文中的AlexNet结构稍有区别:
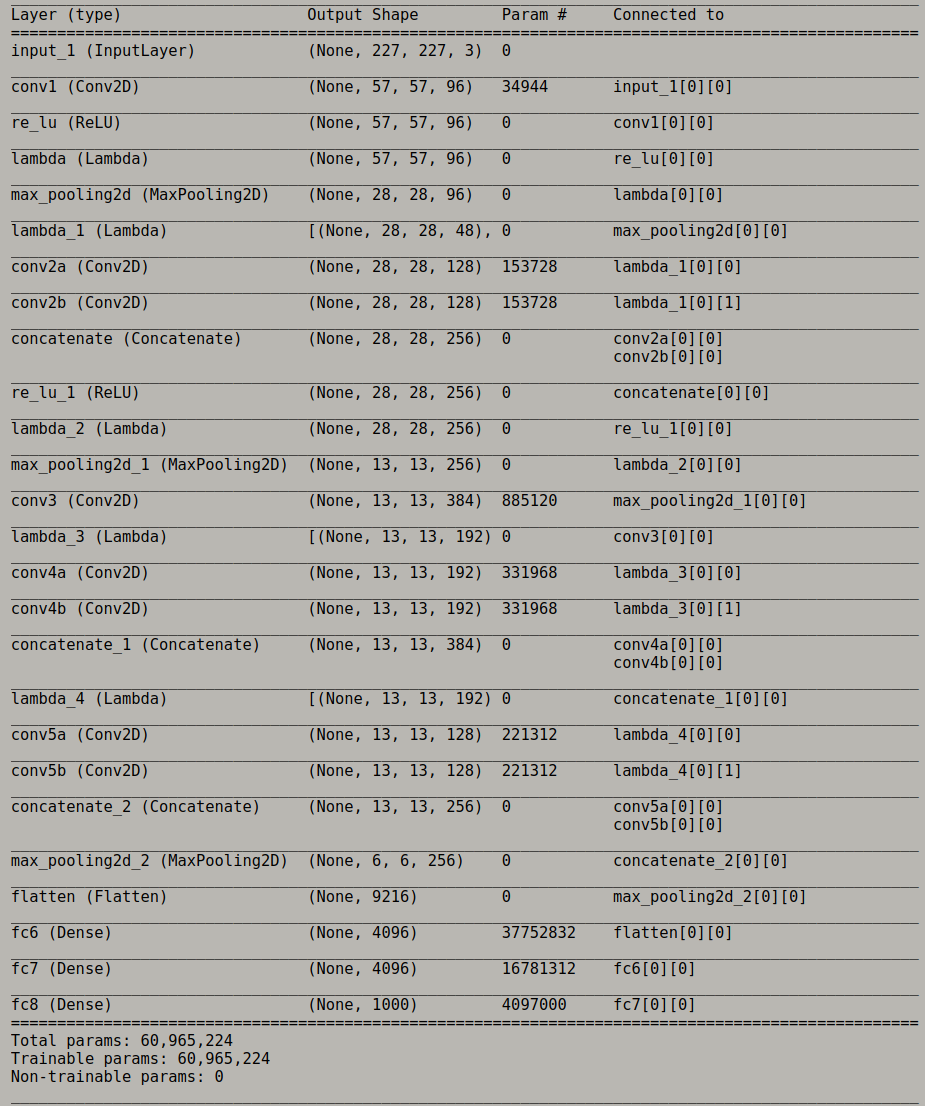
Conclusion
以上简单总结了AlexNet的复现过程。 在Keras中有很多预训练模型,可下载权重后直接加载使用,并可指定仅加载或仅训练某些层的权重,以针对不同的数据集对权重进行精调,使用这些预训练模型时只需要处理好数据集即可,具体流程可参考这里。