本篇文章观点仅限于目前的理解,后续若有新的理解,还会继续更新。
Introduce
在CNN网络中,Receptive Field(感受野)是一个很重要的概念。当使用卷积核对原始图像进行逐层卷积时,层数越深,该层特征图上的每个特征点所对应的原图中的Receptive Field也就越大,这也表示该特征点越抽象。
对某一特征图上的特征点对应到原图中的Receptive Field,该特征点实际上是该Receptive Field的中心,有研究者发现,Receptive Field越靠近中心的像素,对特征点的贡献越大,因而有了Effective Receptive Field(有效感受野)的概念。
在前面学习YOLOv3和Fast R-CNN等目标检测算法时,作者在设计CNN特征提取网络时就考虑到了Receptive Field。
本文首先介绍两种由特征图计算Receptive Field的方法,然后介绍一下Effective Receptive Field的原理,最后对YOLOv3中的网络进行分析。
Receptive Field Calc: Method 1
首先给出卷积操作中输出feature map大小的计算公式:

假设输入feature map和卷积核都是正方形,如下图所示,下图中是feature map的感受野的两种分析方式。
输入feature map大小为5*5,卷积核大小k=3*3,padding=1,strides=2,经过一次卷积后,得到大小为3*3的绿色的特征图,再次卷积,得到大小为2*2的橙色的特征图:
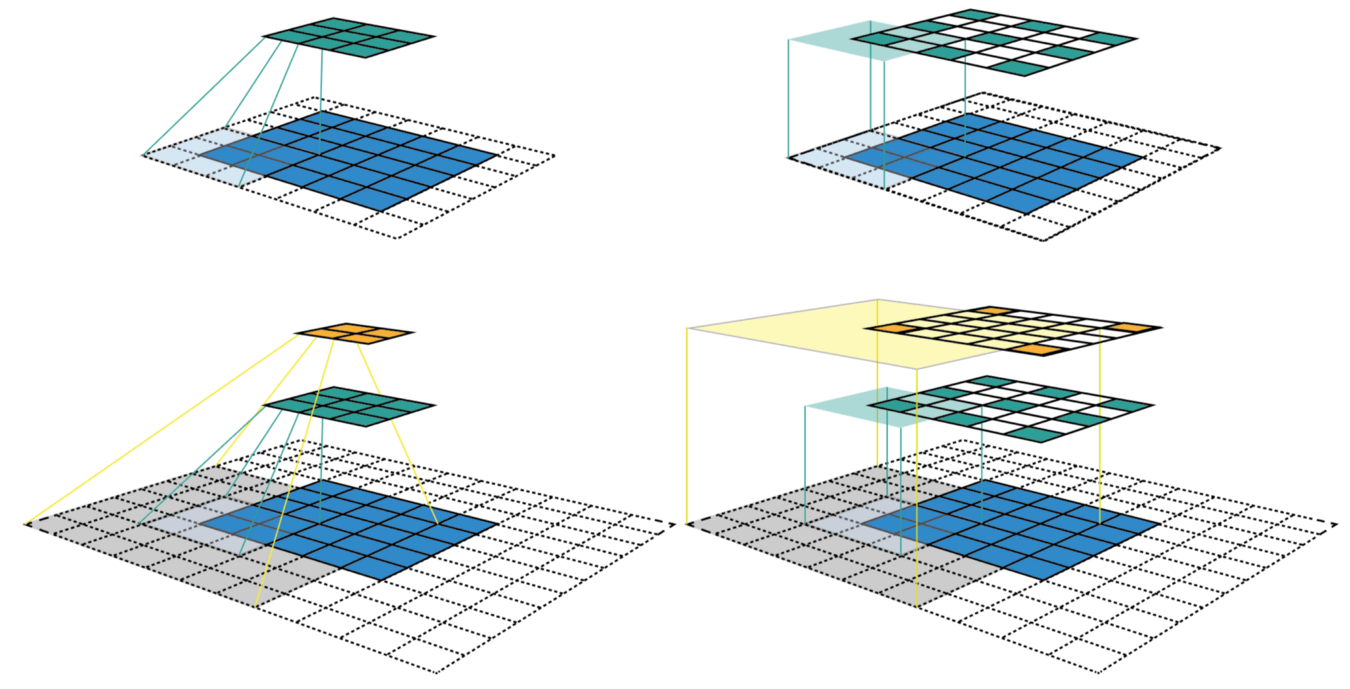
上图中左侧是CNN特征图可视化最常用的方式,图中的映射关系表明了每个特征点所包含的特征数,但这种方法很难判断每个特征点的感受野的中心位置和大小。 上图中右侧给出的是固定特征图大小的CNN可视化方式,所有的特征图保持与最原始的输入一致。由于每个特征点都是该层特征对应感受野的中心,所以通过以某个特征点画框可以方便地找到该层特征对应的感受野。
对上述第二种方式,可以推出相应的计算公式以迭代计算每一层特征点的感受野。
n: feature map每个维度的大小r: 当前层feature map的感受野大小j: 两个相邻特征D点的跳跃距离(上图中特征点间的白色方格)start: 左上角第一个特征点的坐标,也即其对应感受野的中心坐标。该项与r结合可获取当前特征点的感受野的大小和位置,该项与j结合又可获取下一个特征点的位置,以此类推。
计算公式如下:
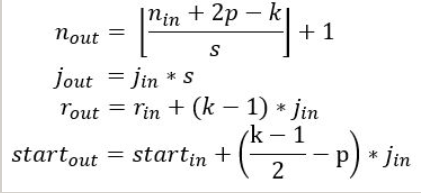
- 第一个式子用于计算当前层输出feature map的大小;
- 第二个式子计算输出feature map的特征间的间隔j,该值将按照步长指数增长;
- 第三个式子计算输出feature map的感受野大小,该值也呈指数增长
- 第四个式子计算输出feature map的第一个特征点的坐标;
- 对第一层,各项初值一般为
n=img_size, r=1, j=1, start=0.5。
上图中的感受野的具体计算过程如下图所示:
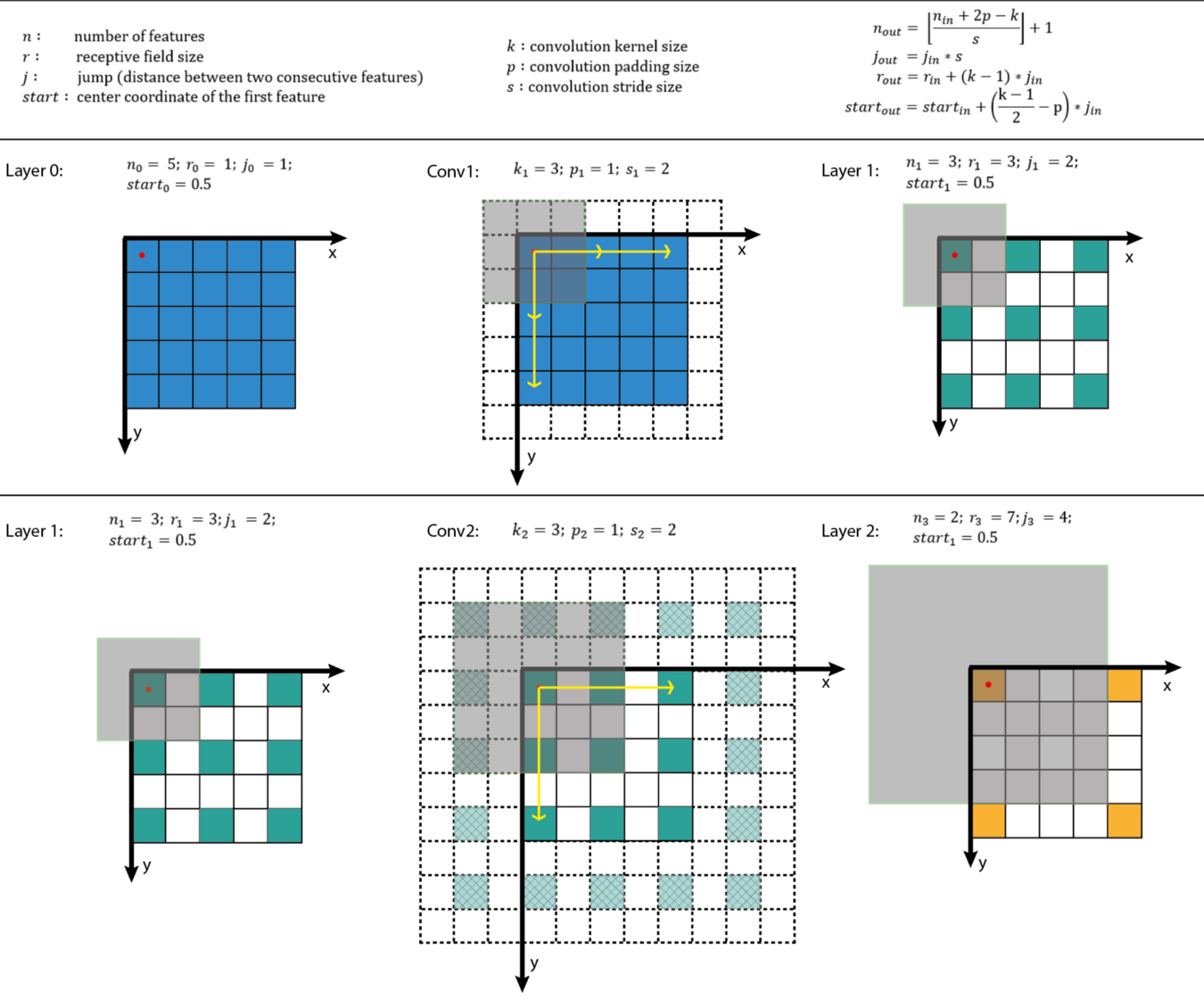
按这种方式去分析常用的k=3*3, padding=1, strides=1的卷积前后feature map大小不变的卷积,仅第三个式子中感受野在以每层增加2的速度递增(上下左右各增加一行),其他参数都不变,这和直观的感受是一致的。
上述分析并未提到pooling操作,实际上pooling操作按照为k=2*2, padding=0, strides=2的卷积来计算。
Receptive Field Calc: Method 2
对于第k层的感受野大小,还有一种更为简单的计算公式:
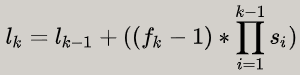
l_(k-1): 第k-1层感受野的大小f_k:当前层卷积核大小s_i: 第i层步长

仔细分析可以发现,该公式实际上就是第一种方法中公式2和公式3的合并,若仅需计算感受野大小而不需计算每个特征点的感受野位置,这个公式会简便一些。
Effective Receptive Field
从CNN对图像的操作来看,Receptive Field可以视为feature map中某个特征点的响应所对应的图像区域。而在CNN中,卷积、池化等操作都会增加特征点所对应的感受野的大小,因此越高的层对应的感受野越大,相应的特征也就越抽象。
而通过直观的感受可以想象,位于感受野中心的像素值由于经过多次卷积都位于中心,所以其对最终的响应值的贡献会多一点,而位于边界的像素值的贡献就会少一些。也即,感受野对于特征点相应值的贡献趋于一种高斯分布而非均匀分布。
这篇论文中有详细的推导,这里只进行直观理解。

Receptive Field for YOLOv3
YOLOv3中,三个分支分别使用了不同尺度的anchor,前面是根据输出层的feature map的大小来进行解释的,feature map较小的使用较大的anchor以检测较大物体,而feature map较大的使用较小的anchor以捕捉较小物体。
这一点也可以从Receptive Field的角度来解释。feature map较小的经过的卷积层数更多,每个特征点所对应的Receptive Field的大小越大,可以覆盖较大物体,所以在这些feature map上可以使用较大的anchor检测大物体,反之亦然。