本篇文章观点仅限于目前的理解,后续若有新的理解,还会继续更新。
1. Introduce
本文涉及两篇论文,分别是2017年的MobileNet v1(貌似是2015年就做出来,但是一直没放出来,后来才放到arXiv上)和2018年CVPR的MobileNet v2。 MobileNet提出的目的是通过优化网络结构,使得在保证一定精度的情况下尽可能减少网络参数和降低计算量,以便在嵌入式设备中运行。
MobileNet v1比较简单,仅仅是深度可分离卷积,MobileNet v2则稍微复杂一点。 本文简述MobileNet v1的思路,并重点介绍MobileNet v2。
2. MobileNet v1
如果读了Xception,觉得MobileNet v1并无新颖之处。
-
MobileNet v1中基本所有的卷积使用的都是
depth-wise convolution深度可分离卷积(类似Xception中,先3*3,再1*1),通过作者在论文中的分析可发现,这种depth-wise convolution可大大降低参数数量和计算量,这里不再赘述。 -
MobileNet v1中的ReLU使用的是ReLU6 = min(max(feature, 0), 6),使得输出限制在[0, 6],在进行量化时,可以避免因为输出较大而造成的精度损失。
另外,作者引入了两个超参数用于控制网络规模,这两个超参数分别用于控制feature map的channel和width相对基础模型的比例,进而控制网络整体的规模,这种思路在前面有些网络的设计中也有使用(暂时忘记是哪个网络了)。
MobileNet v1使用TensorFlow实现起来也并不麻烦,本文给自己的启发应该是实验的设计,这样一个简单的想法,如何通过设计出有对比性的实验来评价模型的性能并得出一系列有说服力的结论。
3. MobileNet v2
相比于MobileNet v1,MobileNet v2的主要改进是添加了线性Bottleneck和使用残差结构。
3.1 Linear Bottlenecks
在Inception结构提出时,它的作者认为具有较多channel的feature map所包含的信息有冗余,可以使用1*1卷积将它们映射到较少channel的低维空间上,该1*1卷积层也通常被称为Bottleneck。
在这篇文章中,作者认为,如果在channel较少的低维张量中使用1*1卷积和ReLU,ReLU的使用会带来较大的信息损耗,例子如下:
 在上图中,二维空间(也可能是三维空间)中的螺旋线所对应的张量使用一个
在上图中,二维空间(也可能是三维空间)中的螺旋线所对应的张量使用一个N*2维的随机矩阵T将其映射到N维空间,在进行ReLU后使用T的逆将其映射回二维空间,可以发现,当N越小时,所造成的信息损失越严重。上述过程就相当于是将一个channel较少的低维张量映射到高维后再映射回低维,在高维中ReLU的使用造成了信息的损耗。
因此,在本文中作者提出,使用线性变换代替原来的1*1卷积中的激活层(即1*1卷积中不再使用激活函数),而在需要使用激活层的张量中,首先使用较大的N将该张量扩张到高维,具体示意图如下:
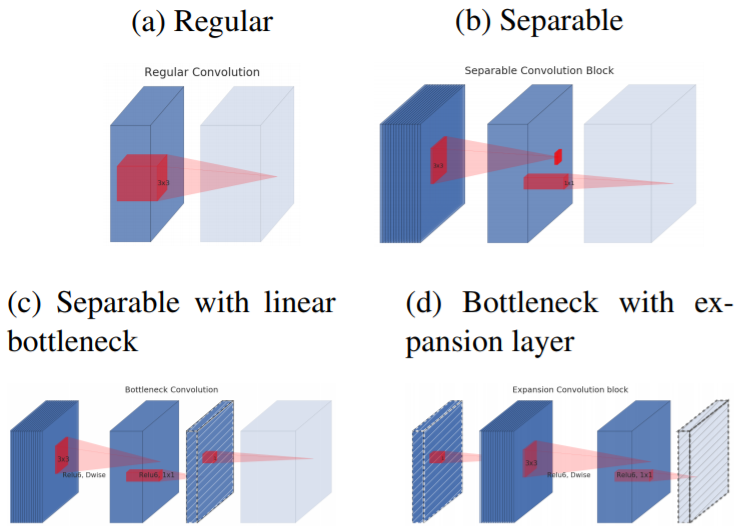 (a)是常规的卷积操作;
(b)是常规的可分离卷积操作;
(c)是具有linear bottleneck的可分离卷积操作,与(b)相比的区别是,这里从低维到高维进行扩张时没有使用激活函数;
(d)是首先对低维张量进行没有激活函数的扩张,在高维空间中进行可分离卷积,最后再映射到所需大小。若是分别对(c)和(d)两种结构进行堆叠,可发现二者是等价的。
(a)是常规的卷积操作;
(b)是常规的可分离卷积操作;
(c)是具有linear bottleneck的可分离卷积操作,与(b)相比的区别是,这里从低维到高维进行扩张时没有使用激活函数;
(d)是首先对低维张量进行没有激活函数的扩张,在高维空间中进行可分离卷积,最后再映射到所需大小。若是分别对(c)和(d)两种结构进行堆叠,可发现二者是等价的。
(以上内容还是稍有疑惑。)
3.2 Inverted Residual
目前的网络结构设计中,残差结构已经成为必不可少的成分,在MobileNet v2中,作者也使用了该结构。
如下图所示,与普通的残差连接不同的是,作者这里将残差结构连接在两个低维张量间:
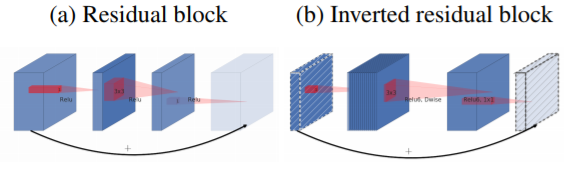
综合以上两点,作者给出MobileNet的基础网络结构Bottleneck residual block:

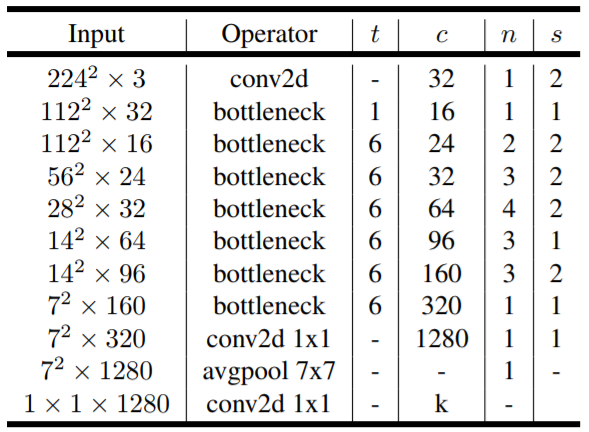
3.3 Overall Architecture
MobileNet v2总体的网络结构如下,其中,t为扩张系数,c为channel数,n为重复次数,s为步长:
4. Conclusion
深度可分离卷积使得网络性能在下降不大的情况下参数数量大量减少且速度有较大提升,MobileNet充分体现了这一优势,这里的实验部分不再赘述,后期会尝试复现其结果。
5. MobileNet V3
使用神经结构搜索(NAS)来找出MobileNet V3的结构
0.网络的架构基于NAS实现的MnasNet(效果比MobileNetV2好)
1.引入MobileNetV1的深度可分离卷积
2.引入MobileNetV2的具有线性瓶颈的倒残差结构
3.引入基于squeeze and excitation结构的轻量级注意力模型(SE)
4.使用了一种新的激活函数h-swish(x)
swish函数(搜索出来的?)

因为swish在嵌入式设备上不友好,因此给出了hard-swish

5.网络结构搜索中,结合两种技术:资源受限的NAS(platform-aware NAS)与NetAdapt
6.修改了MobileNetV2网络端部最后阶段