本篇文章观点仅限于目前的理解,后续若有新的理解,还会继续更新。
1. Introduce
SENet是CVPR2017上的一篇文章中提出来的,该网络获得了ILSVRC2017的Classification任务的冠军。
SENet的motivation是如何加强feature map各通道之间的联系,使得在一个中feature map能够提高信息量较大的channel所占的比重而削弱信息量较小的channel,从而提高网络的表达能力。 作者指出,在卷积核对feature map进行卷积的过程中,实际上已经隐含了对feature map各channel信息的融合,但该融合仅限于卷积核覆盖的一小部分,而非全局的。
因此,作者提出了Squeeze-and-Excitation操作,旨在建立起一个feature map的各channel的整体关系。
本文主要对Squeeze-and-Excitation操作进行解析,最后给出作者的一些实验结果。
2. Squeeze-and-Excitation
如下图所示,图中X为输入feature map,经过$F_{tr}$卷积操作后得到输出feature map,SENet中并非把该输出feature map直接送到下一层,而是建立起各channel的关系后对各channel进行一个加权操作,突出信息量较大的特征,抑制信息量较少的特征,最后将经过加权操作后的feature map送入下一层。
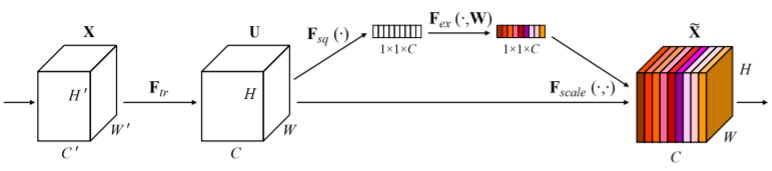
Squeeze: Global Information Embedding 首先是对U中的每一个channel进行一个全局的编码,在论文中作者使用的是全局均值池化,将各个通道的均值信息作为该通道的编码,公式如下:

Excitation: Adaptive Recalibration 在该步中,作者考虑使用上述channel编码来获取一个表达channel间的依赖关系的函数,该函数要既能学习各channel间的非线性关系,又要能保证突出所有信息量较大的channel而非仅仅突出信息量最大的channel。 作者考虑使用两层全连接操作来学习出一个这样的函数,激活函数分别使用ReLU和Sigmoid,r代表一个缩减比例,作者通过实验发现,当r=16时,能够在精度和复杂度上取得一个较好的平衡。

全连接层的输出结果最终作为尺度信息作用到U中的各个channel上,得到的feature map送入下一层,公式如下:
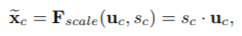
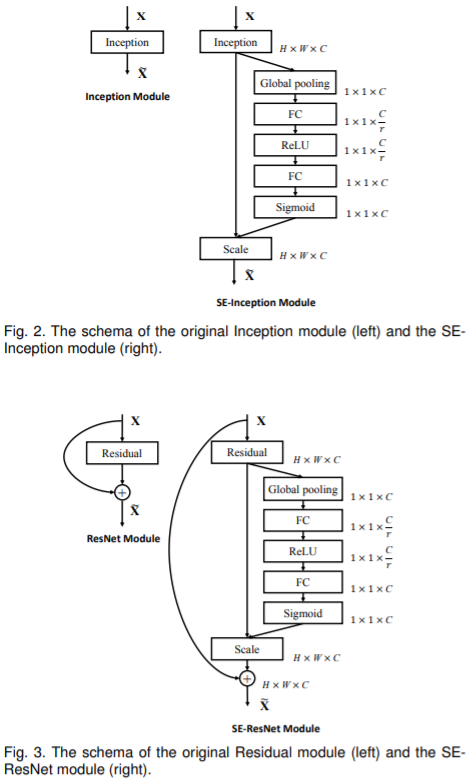
通过上面的分析可以发现,SENet并没有提出新颖的网络结构,而是在现有网络结构的基础上给每一层的输出feature map加上一个SE操作。 以Inception和ResNet为例,相应的SE-module如下图所示:
3. Experiment
作者重新训练了一些经典的网络,并在相应网络上加上SE结构后进行对比,可以发现,SE结构会虽然会略微造成计算量和参数量的增加,但相应的错误率都有大约1个百分点的下降:
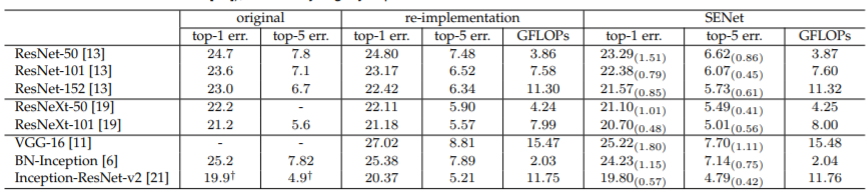

作者的后续实验也表明,该SE结构对其他数据集也有较好的效果,这里不再赘述。