本篇文章观点仅限于目前的理解,后续若有新的理解,还会继续更新。
1. Introduce
ResNeXt是在2017年CVPR上的一篇文章中提出的,该网络获得了ILSVRC-2016的Classification任务的第二名(当年的第一名没有发paper,貌似只是对已有网络进行优化)。
在进行ResNeXt的设计时,作者主要借鉴了VGGNet/ResNet和Inception结构的设计思路。
首先是VGGNet/ResNet,这类网络设计的特点就是简洁,主要使用相同的层进行层层堆叠而成,而Inception结构的设计则相对较复杂,但其主要是使用一种split-transform-merge的策略。
作者把这两种思路进行了结合,在Inception结构中采用类似VGGNet/ResNeXt这样的简单策略,最终提出了自己的Group Convolution模块。
这篇文章与同年的Xception有一些相似之处,二者都认同Inception的split-transform-merge的操作方法,但又对Inception中各个路径的操作进行统一,且都结合了残差的思想。不同的是,Xception是将Inception中的路径个数推向极致,最终的结果是进行Depth-wise Convolution,通过控制模块的通道个数k来控制网络规模,而ResNeXt则是每个路径对相同数目的通道进行卷积,最终是进行Group Convolution,相当于是介于传统卷积核Depth-wise Convolution之间的一种卷积方式,ResNeXt通过控制组的个数c来控制网络规模。而实际上k和c控制的都是Inception模块中路径的个数。
本文首先介绍作者提出ResNeXt的motivation,然后对作者作者提出的分组卷积模块进行介绍,最后分析一下作者相关的实验结果。
2. Motivation -> Group Convolution
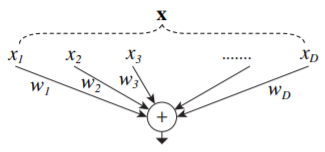
下图是一个简单的神经元内积操作,作者认为该操作可以被抽象为
split-transform-merge三个步骤:
- split: 向量x被分解为小的低维子“向量”x_i;
- transform: 被分解后的各个向量被权重进行了缩放操作,得到w_i*x_i;
- merge: 所有经过变换后的子向量进行合并操作。
作者对上述操作进行了推广,提出了
Network-in-Neuron。 简单来说,就是对输入向量x进行C种不同的变换T_i(不一定是简单的尺度变换),将变换后的结果再进行合并。 作者将C称为cardinality,并将其视为一个超参数。
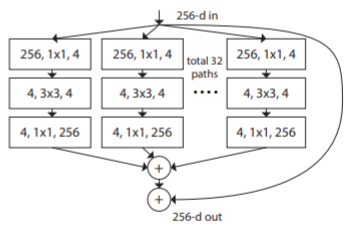
有了上述思想,再结合Inception的设计理念,可以设计出如下图中的结构: 方框中的数字分别表示
in channels, filter size, out channels。 该结构中每一条路径的卷积操作就是上述公式中的变换T_i,共进行C=32次,设计时同时使用了残差结构。
上述结构可使用下图中的结构代替,该结构中首先对卷积结果沿channel方向联合,然后再同一使用
1*1的卷积核进行升维:
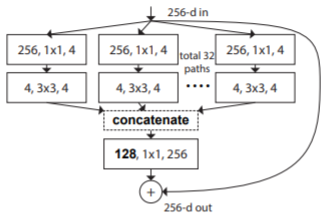
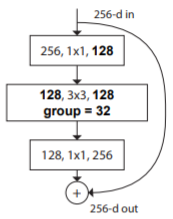
上述结构又可进一步抽象为一个分组卷积操作,输入的256-d特征首先被压缩到128-d,然后分为32组进行分组卷积,每一小组卷积输入为4-d,输出为4-d,所有小组的卷积输出后进行concat操作,然后再使用
1*1卷积核上升到所需维度:
3. Architecture
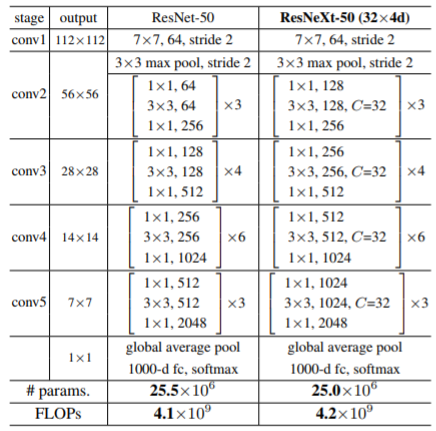
使用分组卷积模块构建的一个与ResNet-50体量相当的网络如下图所示:
使用该模块进行网络构建的优势就是相对简单,作者在构建网络时同时遵循了以下原则:
- 若输出的feature map大小相同,则各模块使用的卷积核大小等参数也相同;
- 若输出的feature map大小减半,则模块的channel加倍以保证各模块的计算量相同;
该设计原则在VGGNet/ResNet/Darknet的设计中都有使用。
4. Experiments
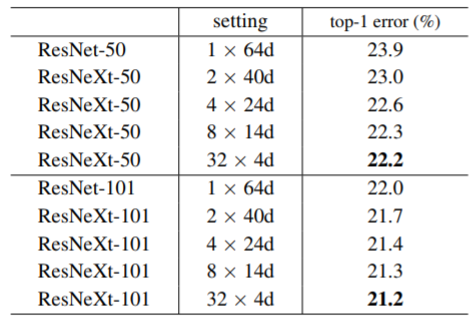
作者将C(模块中的路径数)视为一个超参数,作者通过如下对比实验说明,在计算量相同的情况下,通过提高C(相应地降低每个小组的channel数)可以提高网络的分类精度:
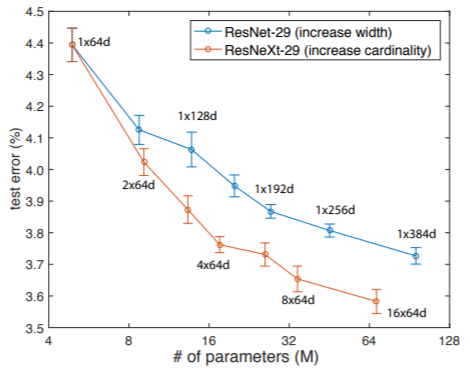
通过在CIFAR数据集上的对比实验也可以发现,通过调节C比调节网络的channel更有效: 从这一点看,是不是Xception的极限情况效果会更好?
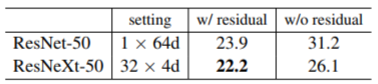
作者在文章中对比说明了残差连接对网络的重要性:
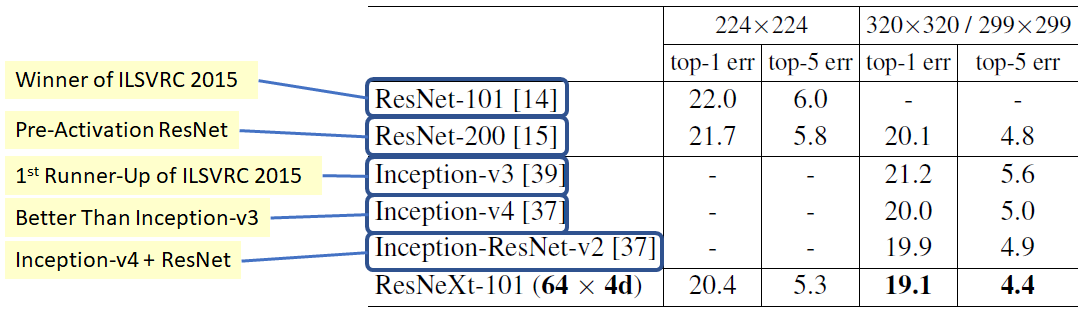
相同体量下,ResNeXt性能最优:
其他实验结果暂时略过
5. Conclusion
这篇论文和Xception可对比来看,都是使用了ResNet的思想,同时目的都是简化Inception结构,最终得到的结论也非常相似,一个是Depth-wise Convolution,一个是Group Convolution。
TODO:复现其在CIFAR数据集上的实验结果。