本篇文章观点仅限于目前的理解,后续若有新的理解,还会继续更新。
1. Introduce
Xception是2017年CVPR上的一篇文章中提出的,作者在Google提出的一系列Inception结构的基础上进行了进一步的发展,将其与基于深度的分离卷积相结合,提出了Extreme Inception,即Xception。
本文首先介绍Depth-wise separable convolution,然后介绍作者提出Xception的motivation,最后对Xception的结构和论文内容进行简单总结。
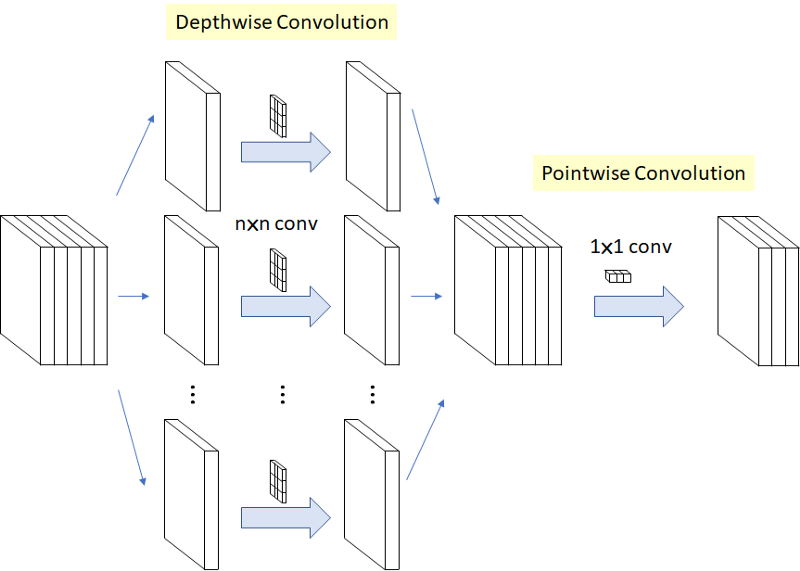
2. Depth-wise Separable Convolution
深度可分离卷积不同于普通的卷积操作,如下图所示,深度可分离卷积首先使用各卷积核按层对输入特征进行卷积,卷积之后组成与输入特征层数相等的特征图,之后再使用1*1的卷积核(Point-wise Convolution)卷积到所需维度:
3. Motivation
一个普通的Inception v3模块如下图所示,通过对Inception网络的学习可以知道,在Concat时,网络中不同路径的卷积结果最终是沿channel方向连接在一起,模块中1×1卷积核的目的是进行降维以对特征进行压缩,同时减少参数数量:
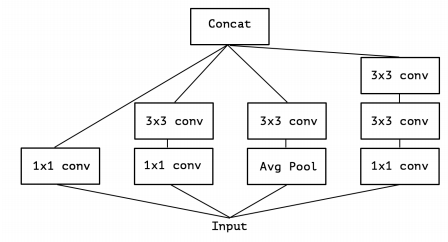
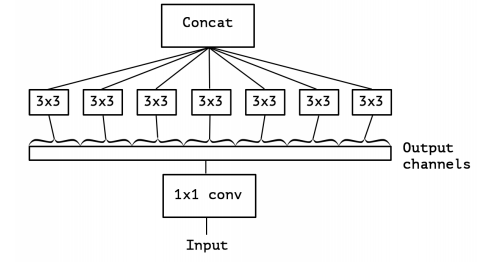
所以可以考虑一种极端情况,每一个通路都使用1个1×1的卷积核压缩输入特征,然后使用1个3×3的卷积核进行卷积,也即每个通路在Concat时只贡献一个channel。
这种极端情况可用下图表示:
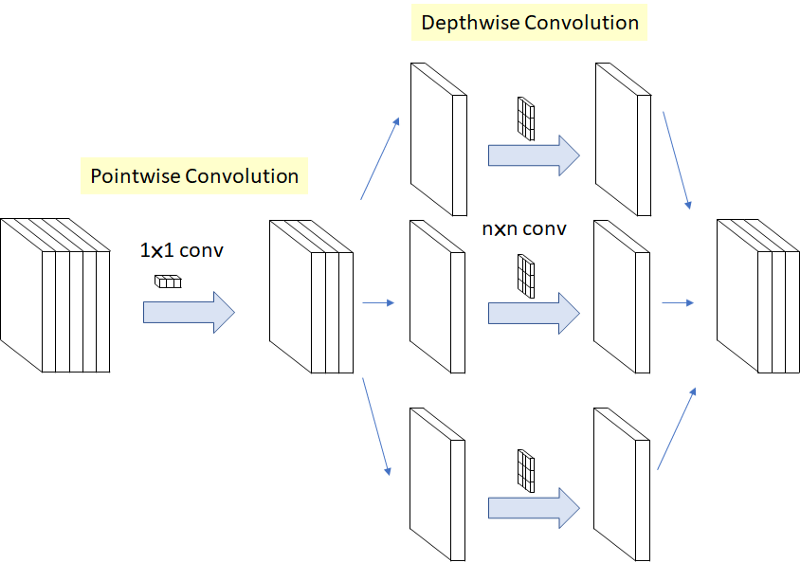
通过上面的思考,作者提出了如下的depth-wise separable convolution,这里的深度可分离卷积和上面提到的略有不同,此处是先进行Point-wise的1×1卷积,再进行depth-wise的卷积:
4. Xception Architecture
最终的Xception网络结构如下,该结构使用了可分离卷积,同时引入了ResNet的残差结构,共有36个卷积层,每层卷积后都使用了BN:
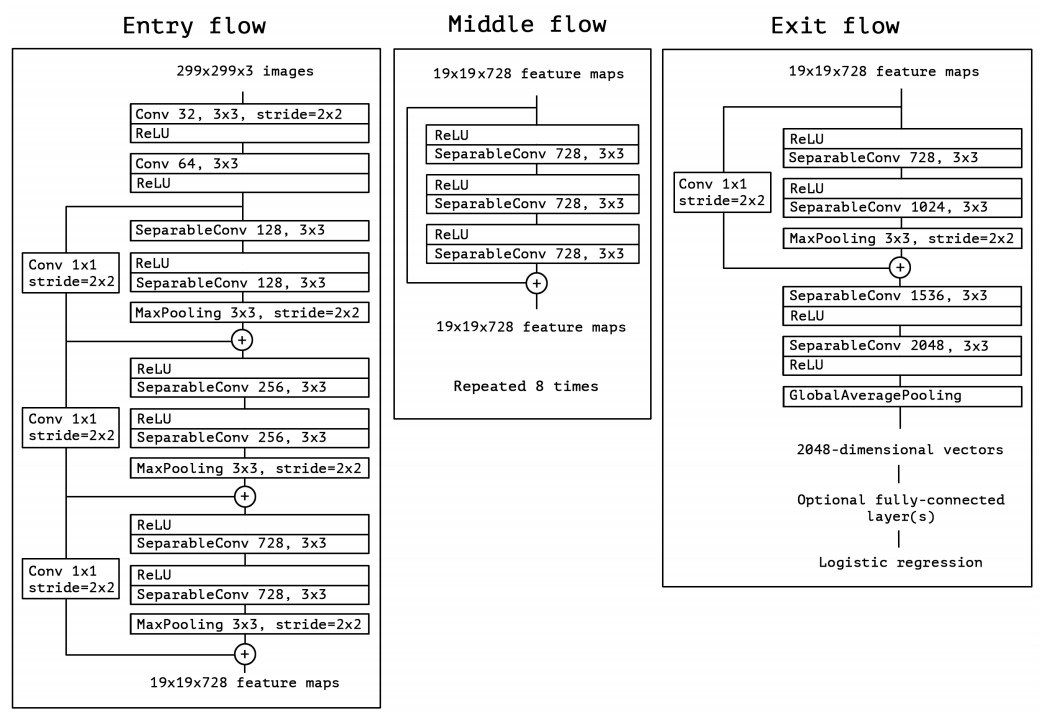
作者给出了Keras版本的实现,网络的其他细节这里不再详述。
5. Conclusion
通过作者在ImageNet等较大的分类数据集上的实验发现,Xception的性能比ResNet-152和Inception v3略好一些,Xception的参数数量比Inception v3略少,最主要的是,Xception比较简洁。在Inception v3中,网络使用多种Inception模块进行构造,如果想构造一个小的网络会有些让人不知道如何下手,相比之下,Xception则要清晰很多。