本篇文章观点仅限于目前的理解,后续若有新的理解,还会继续更新。
1. Introduce
在Fast R-CNN中,检测一张图片一共需要2.3s,但是有2s的时间是用于Selective Search方法产生候选框,主要是因为Selective Search方法不能使用GPU加速。
针对该问题,作者提出Faster R-CNN,整体框架如下图所示,与Fast R-CNN基本相同,唯一的区别是将Selective Search方法替换为一个RPN卷积网络来产生候选框,这使得Faster R-CNN检测一张图片仅需0.2s:
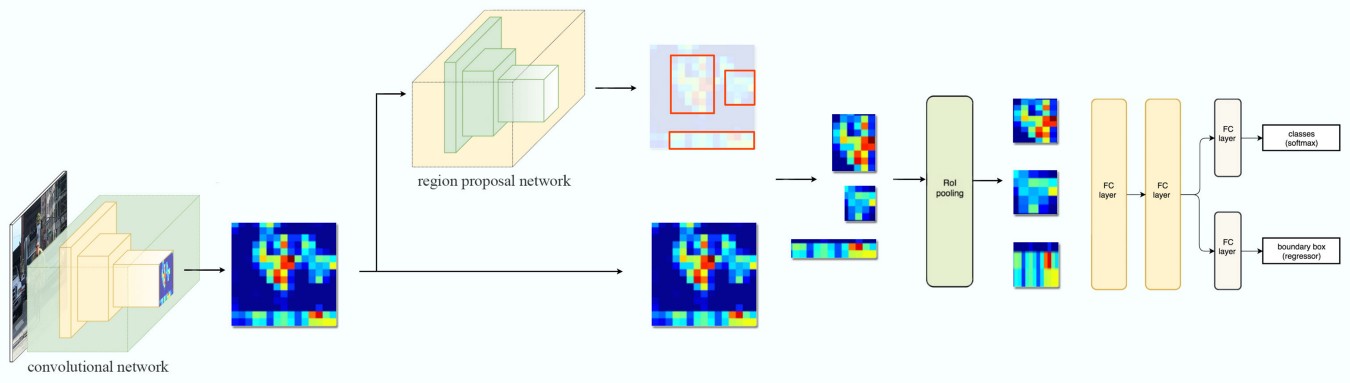
本文主要对RPN网络进行分析
2. Region Proposal Networks
作者提出RPN网络,该网络直接在CNN网络提取到的feature map的基础上进行候选框的预测,而不再像Selective Search方法那样在原图的基础上在原图的基础上进行预测。
根据论文中的叙述,对RPN的理解如下:
- 一个大小为
n*n的滑动窗口(论文中为3*3)在卷积网络输出的feature map上滑动,步长为1; - 对每一个
3*3的区域,使用256个3*3*c的卷积核(ZFNet:256, VGGNet:512)对该区域进行卷积,生成1*1*256的特征向量; - 该特征向量分别连接至两个全连接网络(
1*1*2k和1*1*4k),一个输出为2k(k个候选框,每个框有物体/没物体的概率),一个输出为4k(k个候选框的参数:x,y,w,h); - 对滑动窗口所到区域,都进行上述操作,也即整个特征图共享一个RPN网络参数;
- 若feature map的大小为
H*W,则一共预测出H*W*k个候选框;
3. Anchors
对k个候选框的坐标预测,作者采用了anchor的思想,即预测出的坐标并不是框的实际坐标,而是相对某个anchor的参数值,公式如下:
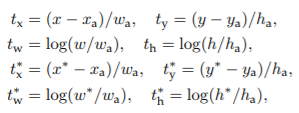 式中,x和x*分别为网络预测参数和实际参数,x_a为anchor的参数(y,w,h同理)。
式中,x和x*分别为网络预测参数和实际参数,x_a为anchor的参数(y,w,h同理)。
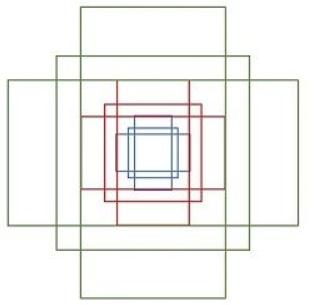
对每个滑动窗口区域,作者预测k=9个候选框,分别对应9个anchors。作者设定anchors的标准为:
- 3个不同尺度:128, 256, 512
- 每个尺度三个不同比例: 2:1, 1:1, 1:2
尺度参数是根据输入图像的大小设定的,论文中将图像的最短边缩放到600后输入到网络(假设约为600*800),这里最大尺度的anchor尺寸为1024*512,512*512,512*256,最大可覆盖整张图像。
在训练RPN网络时,需要根据ground truth计算loss,此时anchors的坐标为当前滑动窗口所在位置的中心点所对应的图像中的位置,相当于下图所示的anchors集合在feature map上滑动,类似于一种多尺度检测:
设置anchor正负的原则为:
- 正anchor:anchors与当前ground truth有最大IoU或anchors与任意ground truth的IoU>0.7;
- 负anchor:当前anchor与任意ground truth的IoU都小于0.3;
- 非正非负的anchors不计入loss计算。
Faster R-CNN中的Loss Function与Fast R-CNN中的类似,这里不再详述。
4. Sharing Conv Features
要注意,Faster R-CNN中RPN网络和目标检测网络共用CNN网络提取到的特征,而二者又是独立训练,所以需要有一定的训练策略来使CNN网络的特征适应这两个检测网络。
作者在文中提到了四种联合训练的方法,这里不再详述。
在目前看来,Faster R-CNN还是有些过时,YOLO系列在此之后提出。总体上看,在读了MultiBox和R-CNN系列的文章后,感觉YOLO的思想不显得太过新颖。