本篇文章观点仅限于目前的理解,后续若有新的理解,还会继续更新。
1. Introduce
ResNet v1是由Kaiming He于2016年发表在CVPR上的文章Deep Residual Learning中提出的,残差学习的方法有效地解决了随着网络深度增加而造成的性能退化的问题,在这篇文章中,最深的网络深度达到了152层。
以该结构为基础的所构建的网络,赢得了ILSVRC-2015的Classilfication/Localization/Detection任务的冠军,同时赢得了COCO-2015的Detection/Segmentation任务的冠军,并且在COCO目标检测数据集上,获得了相对28%的提升。
目前的研究已经表明,提高网络深度可以提高网络性能,但网络较深则会带来梯度消失和梯度爆炸的问题,目前该问题可以通过Normalized Initialization和Batch Normalization很好地解决。
但通过实验发现,不断增加网络深度还会带来网络退化的问题,如下图所示,对CIFAR-10数据集,较深网络的训练和测试误差都比较浅层网络大,造成这一现象的不是过拟合,而是网络退化:
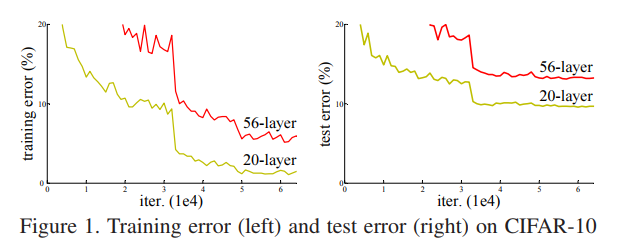
深层网络的误差反而更大,作者对这一问题进行了分析,提出了残差网络的概念。
2. Deep Residual Learning
如果我们假设非线性的卷积网络层可以近似复杂的函数,那么它应该也可以去近似一个恒等映射,即:输入x经过非线性卷积层后的输出仍为x。
基于以上假设,我们在一个已经获得较好性能的浅层网络上继续叠加新的卷积层,这些新加的卷积层都被构造为恒等映射,其他层直接是对原有网络的复制,那么原则上讲,新构造的较深的网络的误差应该不会比原有网络大。
正如上面CIFAR-10的例子一样,通过实验发现,在达到一定精度的网络上继续构造较深的网络,其性能往往不如原有网络,也即出现退化现象。 作者认为出现退化现象说明非线性卷积层在近似恒等映射方面有困难。
仍然是基于非线性的卷积网络层可以近似复杂的函数这一假设,并设原来经过两层卷积所近似的映射函数为H(x),则原则上这两层卷积同样可近似H(x)-x这一残差函数,如下图所示,图中的F(x)即为两个卷积层所要映射的残差函数H(x)-x,则将输入x直接连到输出后,可得到网络的新的输出F(x)+x,对于正常的卷积层(比如上述例子中的浅层网络中的卷积层),该模块的最终映射为F(x)+x=H(x)-x+x=H(x),不受影响,而对于要实现恒等映射的卷积层来说,新的残差结构使得卷积层只需要实现F(x)=H(x)-x=0即可,后面的实验表明,非线性卷积层去近似该残差函数要比去近似一个恒等映射的效果要好的多。
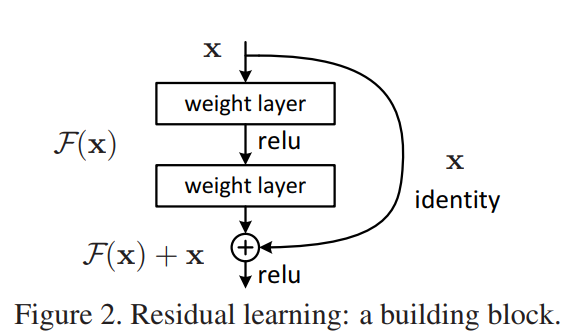
对于以上残差模块,要注意以下几点:
- 输入x与输出的残差连接是
element-wise addition,即对应元素相加,所以要保证输入与输出的shape相同; - 对该模块,经过残差连接相加后,才经过最后的非线性激活函数;
- 论文中单个模块中包含的卷积层的个数为2-3层,如下图所示,论文中较浅层的网络应用左侧模块,较深层的网络应用右侧模块,右侧模块前后两个
1*1的卷积层分别达到降低和提高维度的作用,可用于构建较深的网络: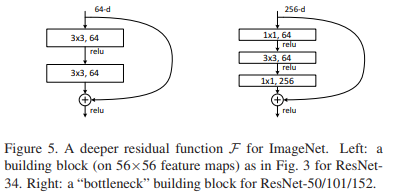
3. Network Architectures
作者的网络设计参考VGGNet中的设计原则:
- 基本使用
3*3的卷积核; - 对于输出的feature map大小相同的层,其卷积核个数也相同;
- 当feature map大小减半时,卷积核个数加倍以保证每一层的时间复杂度相同;
另外,作者使用了步长为2的卷积来进行下采样,并且使用全局均值池化代替全连接层,这使得作者构造的网络达到了34层,而参数数量却只有VGG-19的1/5,如下图所示:
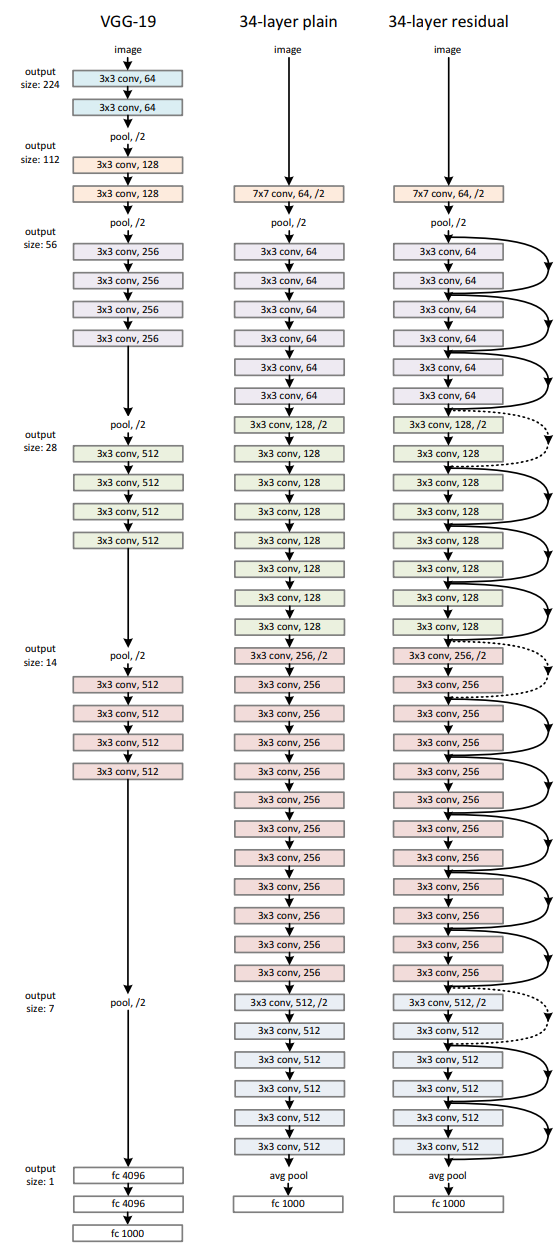
当feature map大小减半时,按照论文中的网络设计,输入k*k*n,输出应为k/2*k/2*2n,此时若要应用残差连接,需要在wh和channel方向进行对应,在wh方向,可以以步长为2进行对应,在channel方向,有以下两种选择:
- 使用0-pad在channel方向进行补齐,不引入新的参数;
- 使用2n个
1*1的卷积; 作者最终采用的方法应该是对输入进行步长为2的1*1的卷积。
直接使用步长为2的1*1卷积会使得特征图中3/4的特征都没有被利用,因此还有其他不同版本的改进,可以将步长为2的3*3卷积放到里面来做(ResNet-B),进一步也可以在右侧使用一个2*2的avgpool操作(ResNet-D)

4. Training & Testing Setting
图像处理方面:
- 参考VGG: 以短边缩放图像至
256, 480这两个尺度,并采样224*224的块; - 参考AlexNet: 图像像素减均值,并参考AlexNet中的颜色增强方法;
网络结构方面:
- 激活函数前使用BN,但没有使用Dropout
训练参数:
- batch=256
- lr=0.1 divide 10 when error plateaus
- momentum=0.9 decay=0.0001
- epoch=6*e4
测试阶段:
- 基于ILSVRC-2012训练集进行训练,相应验证集进行测试
- standard 10-crop testing
- Fully Convolutional form
- average the scores at multiple scales
224, 256, 384, 480, 640(将图像短边放缩至该尺寸,然后采集相应大小的正方形块)
5. Experiments Analysis
下表列出了不同深度的ResNet的详细参数:
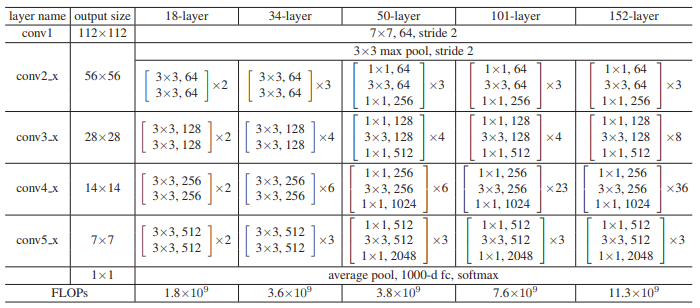
首先对两个较浅层的网络进行分析:
-
如下图所示,细线表示训练误差,粗线表示验证误差,左侧非残差结构的网络,较深的网络的训练和测试误差都比较浅网络大,并且作者认为网络中使用了BN,所以较深网络的这种现象不是由梯度消失造成的;
-
对右侧的残差结构的网络,在feature map不匹配时,作者使用的是维度方向补零的方法以不引入新的参数,对比显示,残差结构在较深的网络结构中很有效;
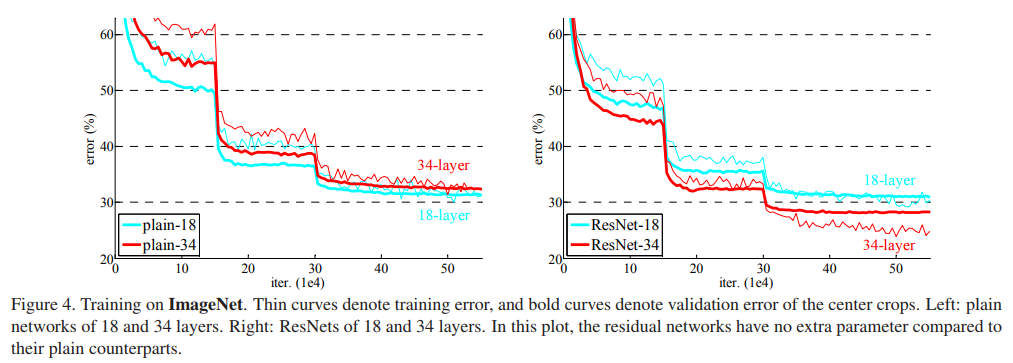
对于较深的网络,作者调整了残差块的设计,也达到了很好的性能,不再赘述;
对于在CIFAR-10数据集上的实验也不再赘述,但是这些经典网络结构的论文,里面的实验设计值得参考。
6. ResNet V2

resnet v1为图a,这里最后relu的位置使得残差块输出永远非负,这闲置了模型的表达能力,作者进行了一系列实验,最终得到e的形式
