本篇文章观点仅限于目前的理解,后续若有新的理解,还会继续更新。
1. Introduce
Inception v1模型是由2015年发表在CVPR上的Going Deeper with Convolutions文章中提出的,文章中首次提出了Inception结构,并把由该结构组成的网络称为GoogLeNet,该网络获得了ILSVRC-2014的Classification任务的冠军。
GoogLeNet达到了22层,在当时应该是最深的网络,由于精心设计的网络结构,其参数数量只有AlexNet的8层网络的1/12,约为500w,并且要比AlexNet更为精确。
作者的motivation是如何在增大网络(depth and width)的同时,不增加运算量。 实验表明,网络越大,效果越好。但是直接加大网络规模会带来两个明显的问题:
- 更易过拟合;
- 计算量增大;
解决上述问题最直接的想法是在卷积层和全连接层都引入稀疏性,用更为稀疏的结构代替传统结构。稀疏的结构也许并不会对模型的效果造成影响,但是现代计算机对非均匀稀疏数据结构的运算效率很差。 有相关实验表明,可以将稀疏矩阵聚类为较为稠密的子矩阵来提供计算性能,所以作者考虑能否找到一个稠密的模块,它能够去近似实现一个最优局部稀疏卷积网络的功能。
作者提出了Inception module结构,它借鉴了NIN的一些思想,网络结构相比于传统的CNN结构有很大改变。网络中大量使用1*1的卷积核,NIN中使用1*1卷积核的目的主要是提高网络的非线性能力,而这里作者用它的主要目的是进行降维,将参数空间进行压缩,去除掉无用的稀疏数据,使参数空间更为稠密,这样可减少参数数量,进而可增加网络的深度和宽度。
2. Inception
根据感受野的概念,较高层的feature map中一个像素点对应于原图的一个区域的信息,所以作者考虑分别使用1*1, 3*3, 5*5的卷积核分别对前一层的feature map进行卷积,以覆盖图像中不同大小的物体,通过padding操作可使输出的feature map的shape相同,然后在channel方向联合这些feature map以作为当前层的输出。
不同大小的卷积核相当于对原图像进行多尺度的处理,后一层在处理时,相当于同时处理了不同尺度图像的信息。
在较高层时特征更为抽象,需要用较大的卷积核来融合不同的特征,所以在较高层时,3*3, 5*5卷积核的数量要多一点。
具体的Inception结构如下图所示:
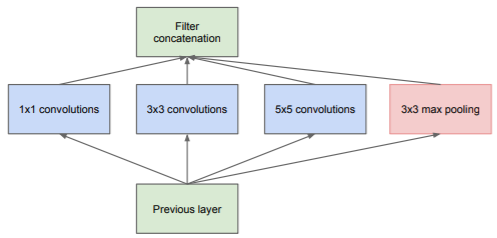
但是这里有一个问题:在较高层时,channel数目较多,5*5卷积操作所带来的计算量非常大,特别是叠加pooling操作后(pooling操作channel数量不变),channel数量会变得非常多。
这里作者提出了第二个版本的Inception结构,引入了1*1的卷积核进行降维。
使用1*1卷积核进行降维源于embeddings的成功:即使是低维嵌入空间也可能包含大量的大块图像的信息。
这里又有一个问题:低维嵌入空间所表达的特征是稠密的、经过压缩过的,一般难以处理,应该要保持特征表达的稀疏性以便于处理。
所以作者又提出的如下的结构,在对输入的feature map进行卷积操作前,先使用1*1的卷积对特征进行压缩,之后的卷积操作相当于又将稠密的特征稀疏化。而在pooling操作时,则是后进行1*1卷积操作,以减少channel数量。
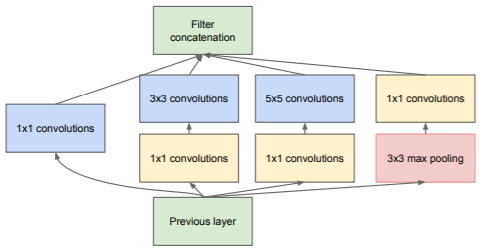
3. GoogLeNet
GoogLeNet便是应用上述Inception结构所构成的网络,只算有训练参数的层的情况下,网络有22层,网络结构可参考论文中的图,具体每层的参数如下表:
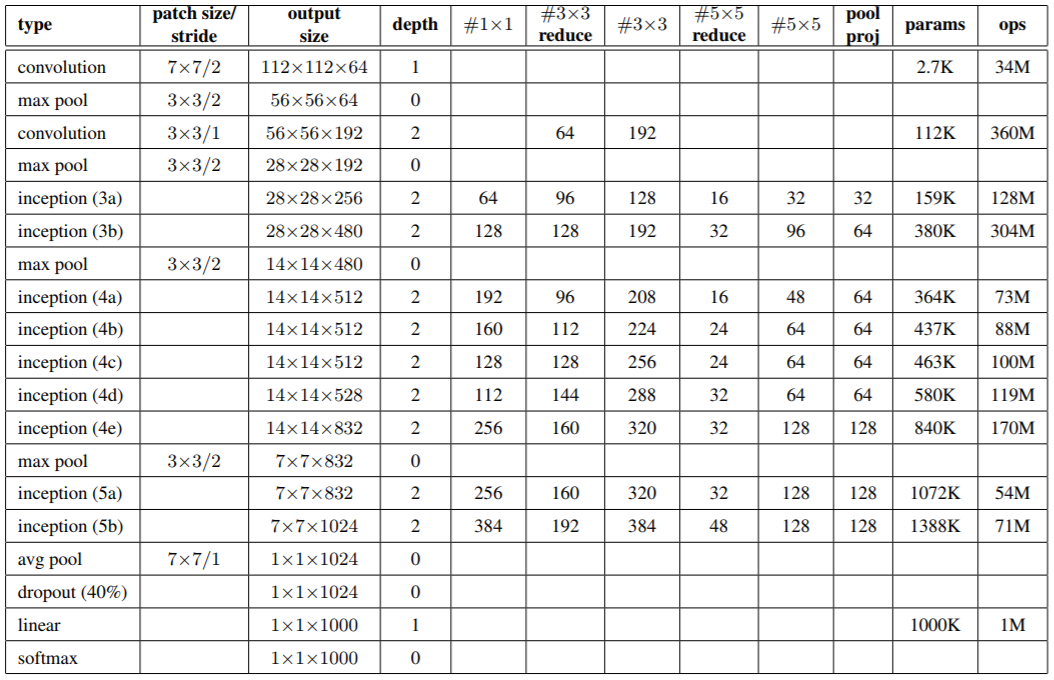
表格中需要注意以下几点:
-
表格中的
#3x3 reduce和#5*5 reduce一栏表示在3x3和5x5卷积前所用的1x1卷积核的数量; -
表格中的
inception(-a/b...)是对feature map大小相同的情况下对使用的Inception模块的编号。 -
Inception结构中的max pooling操作使用的是
3*3的步长为1的池化,而用于Inception之间的则是3*3的步长为2的池化,以缩小feature map的体积; -
网络中使用average pooling代替全连接层用于分类,这给网络性能带来了一定的提升;注意这里的average pooling不同于全局均值池化,此处average pooling后,又对结果进行了线性组合(FC)后才形成最终的分类结果;
-
虽然没有使用全连接层,但是网络中依然使用了dropout层,作者认为这很有必要;
-
网络中也使用了LRN;
-
网络在inference时的计算量约为
1.5 billion multiply-adds;
由于网络层数较深,所以会带来梯度消失的问题。 为了应对该问题,在训练阶段,作者为网络添加了辅助分类器,即使用网络中间某层的feature map进行分类,计算得到的loss以一定权重添加到总的loss中用于训练,在测试阶段则丢弃这些辅助分类器。
GoogLeNet网络分别在inception(4a)和inception(4d)的顶部添加了辅助分类器,其loss按0.3的权重添加到总的loss中。
辅助分类器的结构参考论文。
4. Training
- 输入图像:
224*224*3,均值为0; - momentum = 0.9;
- fixed lr (decreease lr by 4% every 8 epochs);
- 图像采样方法:从图像中采样一定大小(8%-100%)的一定长宽比(3/4, 4/3)的块。
5. Testing
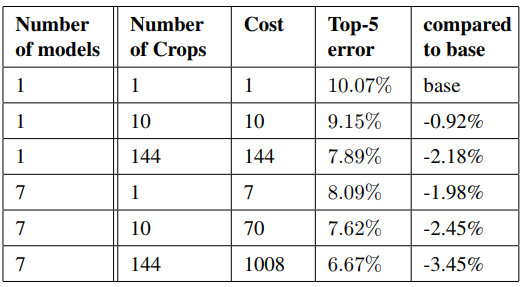
作者在测试时使用了以下策略,以提高模型性能:
-
独立训练7个GoogLeNet模型(6小+1大),模型的参数配置都一样,区别仅在图像采样策略和图像的输入次序;
-
相比于AlexNet,这里在测试时采取的crop更多,策略为:将一幅图像分别resize到四个尺度
256, 288, 320, 352,然后从图像中取左/中/右三个正方形块(若是h>w的图像,取上/中/下三块),然后每个正方形块再取四角和中心224*224的区域和将该正方形块resize到224×224的块,所有这些块再取其水平镜像,所以一幅图像总计取4*3*6*2=144个crops用于测试; -
最终的分类结果是多干crops和多个model分类结果的均值;
下图对比分析了crops和model给模型性能带来的提升:
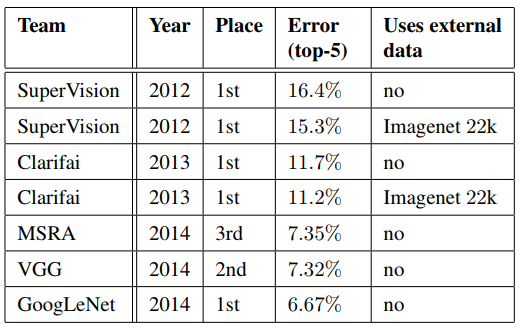
下图是ILSVRC-2014的Classification任务的前三名和往年比赛冠军的对比,其中的SuperVision使用的是AlexNet网络,Clarifai使用的是ZFNet(ZFNet论文中貌似没有在ILSVRC-2013比赛中的成绩数据?):
暂时略过Localization部分