本篇文章观点仅限于目前的理解,后续若有新的理解,还会继续更新。
1. Introduce
VGGNet是在2015年发表在ICLR上的一篇文章中提出的,网络深度提高到了16至19层,在ILSVRC-2014中,基于该网络的方案获得了Localisation任务的第一名和Classification任务的第二名(同年Classification任务第一名为Inception v1方案)。
VGGNet出现前,网络最深也只在10层以内,此时的大多数工作是一方面是使用更小的卷积核和卷积步长,另一方面是使用更大的图像和多尺度对图像进行训练,本文中作者则从另一个角度研究CNN网络的特性–Depth。
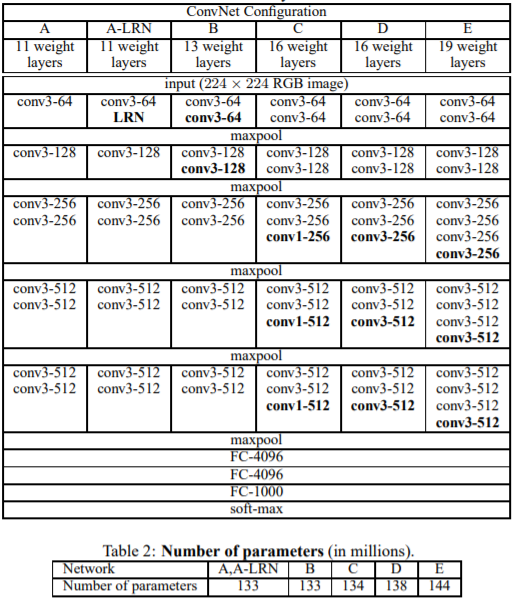
VGGNet的网络结构并没有太多可以分析的地方,作者设计网络的思路也很简单,全部使用3*3大小的卷积核,并在不同的网络结构中加入1*1的卷积核进行对比,剩下的工作就是不断增加网络深度,以分析不同深度对分类精度的影响,如下图所示,VGGNet最深的结构达到了19层,VGG-19 也是现在用的比较多的一个预训练模型,在当时算是比较深的网络,同时也得出结论:较小的卷积核和较深的网络结构可以提高模型精度。
下图为VGG-16的空间直观图:
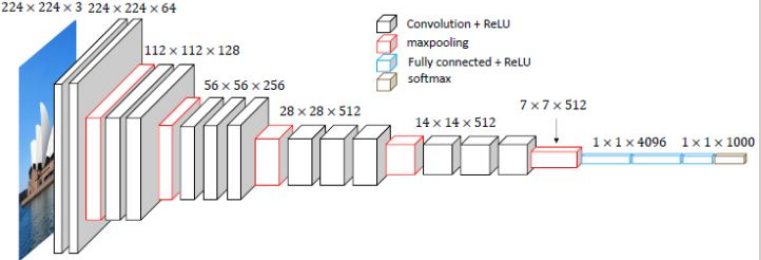
VGG-16的参数数量约为AlexNet的3倍。 下面主要分析一下论文中实验部分的内容。
2. Training
- 参数设置
- batch size = 256
- momentum = 0.9
- L2正则化项
- 前两层全连接层使用Dropout = 0.5
- learning rate = 1e-2 验证集精度停止增加时,lr降低十倍
-
模型初始化 这里作者使用的策略是:首先训练较浅的网络,在训练较深的网络时,使用较浅网络的一部分权重去初始化较深的网络,其他权重使用满足高斯分布的随机值进行初始化,bias初始化为0。
- 图像增强 作者使用了随机翻转和随机像素值漂移等图像增强方法,这里主要介绍作者对图像尺度的处理方法。
在训练时,所有的VGGNet结构都使用224*224大小的图像作为输入,该大小的图像并非直接从原图像裁剪得到,而是先将原图像放缩至尺度S(S>=224),然后再在S中随机裁剪出224*224的图像作为网络输入。
将图像放缩至S的方法与NI论文中的类似:首先将图像的较短边缩放至S,长边按比例缩放至相似长度。
将图像放缩至S,在训练时有以下两种考虑方式:
-
Single Scale: 该种情况下,在整个网络训练过程中,S始终为固定值,论文中选用的为256或384;
-
Multi Scale: 该种情况下,网络在对每个batch的图像进行处理时,先从某一个范围内选出一个S,然后将图像缩放至该S尺度后再从中裁剪图像,论文中选用的范围为
[256 512]。
3. Testing
-
测试前的处理 在网络训练完成后,作者对网络进行了一些处理,以使网络可以处理任何大小的图像。 如下图所示,下图是VGG-16全连接层部分的示意图,
7*7*512是输入第一个全连接层的feature map,在训练时,是将该feature map展开后与全连接层相连,参数数量为7*7*512*4096。 在Testing阶段,作者将其转换为4096个7*7*512的卷积核,与输入feature map进行卷积,得到1*1*4096的feature map,后面的全连接层进行相同的转换,此时该网络相当于变成了一个全卷积网络,最后一层进行Global Average Pooling操作以进行分类,可以不用考虑输入图像的大小。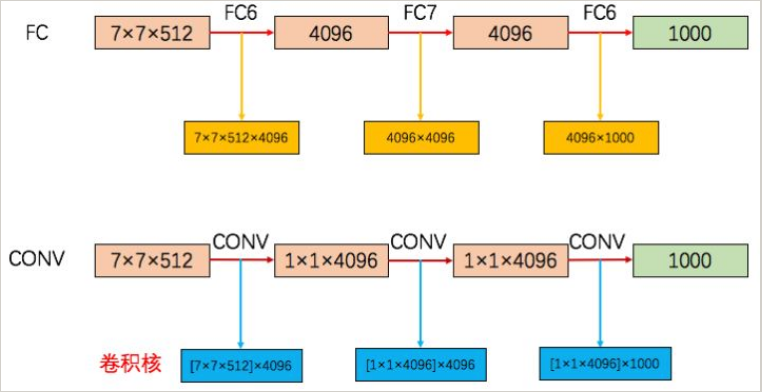
- Single Scale Evaluation
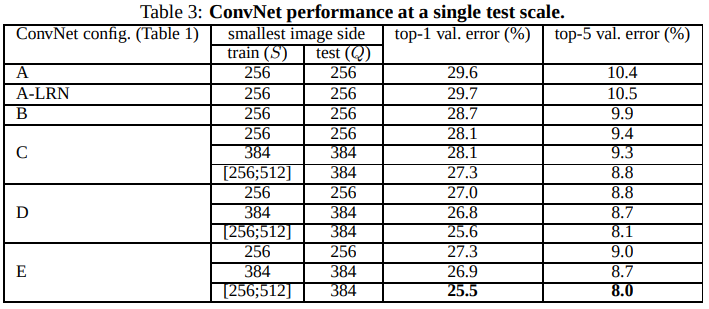
对模型进行单尺度训练和多尺度训练后,使用单尺度对模型进行评估,作者分析得到以下三条现象:
-
加入LRN后,并未提高模型准确率,反而增加了计算量,所以作者在后面的模型中不再使用LRN;
-
分类错误率随着模型深度的增加而减少,但对一定量的训练数据,应该由对应的饱和深度,而不是越深越好。并且,在未达到饱和深度前,相同深度的模型下,
3*3的卷积核比1*1的卷积核更有效,这是因为3*3卷积核可以捕捉到更多的空间上下文信息;、 -
多尺度训练能明显提高模型的准确率;
-
- Multi-Scale Evaluation
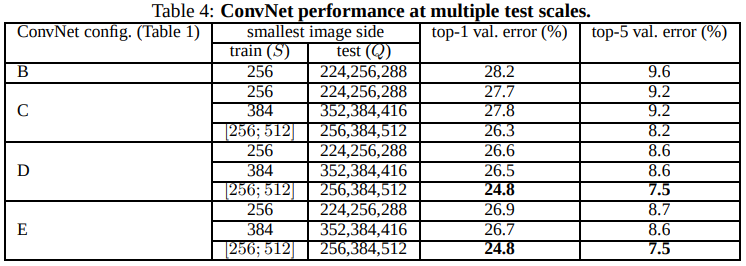
这里要注意概念的区分,这里的Multi Scale Evaluation指的是同一张图片,缩放到不同的大小后进行多次test,并将所有测试结果求均值后作为最终的分类结果,论文中,对一张图片使用三个不同的尺度进行评估,对单尺度训练的模型,
Q={S-32, S, S+32},对多尺度模型,Q={Smin, 0.5(Smin+Smax), Smax}。 经过分析可发现,经过多尺度训练且进行多尺度测试的模型,效果明显要好一些。
- Multi-Crop Evaluation
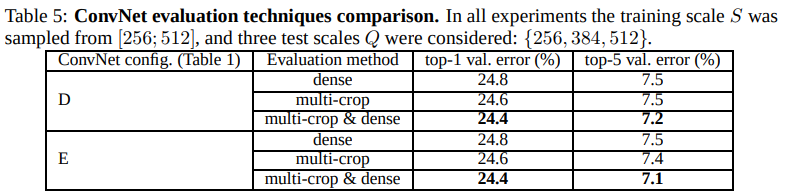
这里的Dense Evaluation是利用FCN的思想,直接将原图送入网络进行评估,而Multi-Crop Evaluation指的是在一幅图像上随机裁剪出不同的crop送入网络进行评估,评估结果求均值后作为最终结果。
经过对比,Szegedy et al.在2014年提出的
Multi-Crop Evaluation相比于Dense Evaluation效果要好一些,它相当于时对Dense Evaluation的补充,二者的区别是在对边界的处理上(一个相当于边界补0,一个相当于边界补充相邻像素值,不是太理解??)
- ConvNet Fusion 多模型融合方法,即使用不同的模型对同一幅图片进行预测,对每个模型的输出求均值后作为最终的分类结果。 该方法对模型精度的提高有帮助。
4. Localisation
VGGNet在ILSVRC-2014的Localisation任务中获得冠军,其使用的定位方法是基于ILSVRC-2013的Localisation任务的冠军方案OverFeat的改进。