本篇文章观点仅限于目前的理解,后续若有新的理解,还会继续更新。
1. Introduce
ZFNet是由2014年发表在ECCV上的一篇文章中提出的,论文的motivation主要是想知道卷积后每层的feature map到底提取到的是什么样的图像特征,所以作者提出了一种反卷积的可视化方法,通过反卷积(Deconvolution),可以将任意的feature map映射到输入层(如224x224x3大小),将映射后的结果绘制出来便实现了相应feature map的可视化。
作者将这一可视化技术应用到AlexNet中,通过对feature map的可视化分析去调整AlexNet卷积核的大小等参数,最终的网络结构获得了ILSVRC-2013 Classification竞赛的第一名(同年Localisation任务第一名为OverFeat方案)。
本篇博客主要从以下两个方面对论文进行总结:
- Deconvolution: 反卷积技术的实现原理
- Convnet Visualization: 对可视化图像的分析方法
2. Deconvolution
为了弄清每层的feature map都提取到了什么样的特征,作者借鉴了反卷积(Deconvolution)相关的工作,并结合目前卷积网络的特点,提出了自己的Deconvolution方案,以实现将某个feature map映射到输入像素空间进行可视化。
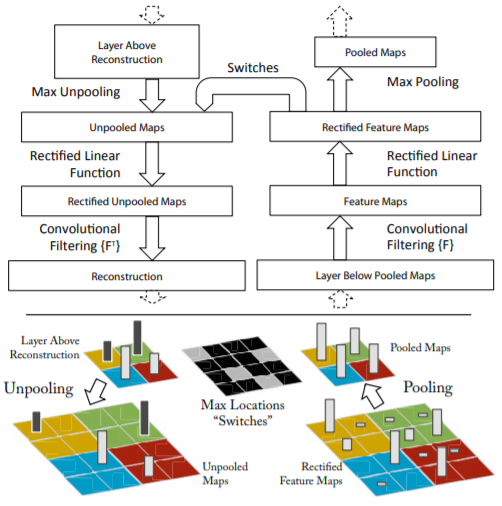
卷积网络生成feature map一般要经过卷积、非线性激活函数、池化这三个步骤,此处的Deconvolution便是将该操作反向进行。如下图所示,图的右侧从下往上看,是一个正常的卷积过程,得到的feature map经过左侧的Deconvolution过程可得到原始输入的近似,主要分为以下三步:
-
Unpooling: 这里是以Max Pooling为例,在正向卷积进行Max Pooling得到feature map时,仅保留filter区域大小的最大值,并使用switch variable来记录最大值在原feature map中的位置,在Unpooling时,可根据这些位置恢复出一个近似的feature map(如示意图所示,非最大值的位置全为0);
-
Rectification: 这里是正向激活函数为ReLU的情况。正向时,卷积结果经过ReLU后,输出的全为正值,所以作者认为需要在Unpooling后再添加一个ReLU,以确保输出的值都为正值。(这里有疑问,正向输出都为正,即max pooling后的结果也为正,若在Unpooling过程中,非最大值位置都设为0,那此处的ReLU的设置就是没意义的?);
-
Filtering: 此处是使用正向过程中使用的卷积核进行卷积,由于是逆过程,作者这里使用了卷积核的转置(水平和竖直方向翻转)。这里曾困惑于feature map和卷积核通道个数不匹配的问题,给一个实例推导一下即可,中间层任意一个feature map都可以推导到输入像素空间,得到与原图相同大小的特征图。
3. Convnet Visualization
作者首先对图像行了一些预处理:以图像最短边为基准,将最短边缩放至256,然后长边按比例缩放,并提取出缩放后图像中心的256*256的区域。在训练时,每次从该区域随机裁剪出224*224大小的区域用于训练。
作者通过对feature map的可视化,主要进行了以下分析:
-
Feature Visualization: 通过对某一层激活值最大的前几个feature map进行可视化,可以大概分析出每个feature map提取到了图像的哪些特征,这里的激活值,应该是使用每个feature map所有值累加和进行对比;
-
Feature Evolution: 如下图所示,下图的每一行表示同一feature map在训练次数增加过程中中的变化。可以发现,较为浅层的feature map可以较快达到收敛,而layer 5等较为深层的feature map需要更多次训练才能达到收敛;

-
Feature Invariance: 这里作者分析了平移、旋转和缩放操作对模型精度的影响,发现模型具有平移和尺度不变性,但对旋转适应性较低;
-
Architecture Selection: 通过可视化AlexNet各层的feature map,作者发现AlexNet的前两层即包含了高频也包含了低频特征,于是作者将卷积核和卷积步长调小后,这一问题得到解决,模型精度也有所提升。这里给出了一个模型训练的思路,即可以通过分析不同层的feature map特点来调整模型参数;
-
Occlusion Sensitivity: 作者思考模型实现对物体的分类,是仅仅利用图像的环境信息,还是真正检测到了物体的位置。于是作者使用一个灰色块遮挡图像的不同区域,发现遮挡物体后,精度有所降低,得到的结论是,模型对物体实现分类是定位了物体的位置;(?)