本篇文章观点仅限于目前的理解,后续若有新的理解,还会继续更新。
1. YOLO的创新点在哪里?
这里一般都会与R-CNN系列的目标检测系统进行比较,但是目前自己对R-CNN理解有限,不做深入分析。 YOLO最主要的创新点,就是作者在论文中所说的,把目标检测看做一个回归问题:
We frame object detection as a regression problem to spatially separated bounding boxes and associated class probabilities.
我们知道,分类问题处理的对象是离散值,回归问题处理的对象是连续值,而在目标检测任务中有对bounding box坐标的预测,作者这里就是考虑在网络的最后使用两个全连接层作为一个线性回归器,对bounding box的坐标和物体类别进行回归。
2. YOLO的基本网络结构是怎样的?
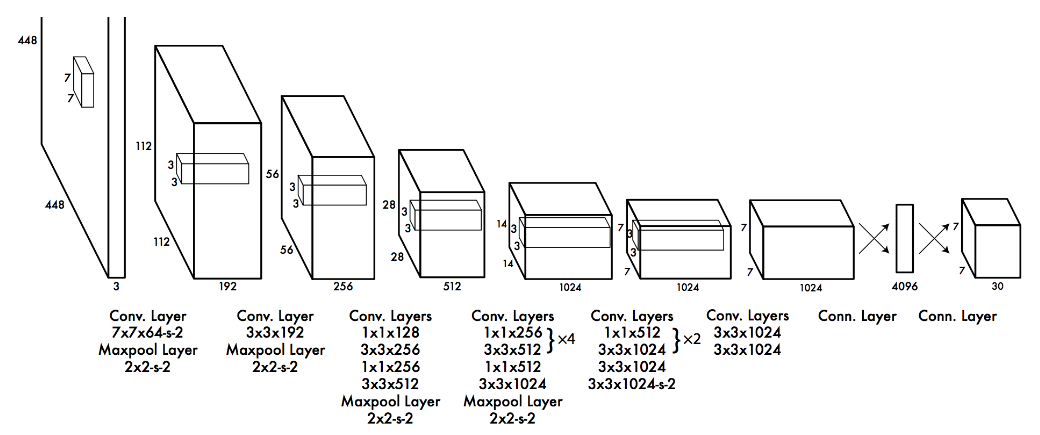 YOLOv1的基本网络结构如上图所示,共有24层卷积层和2层全连接层,图片下方参数中的
YOLOv1的基本网络结构如上图所示,共有24层卷积层和2层全连接层,图片下方参数中的s-2指的是步长为2,这里要注意以下三点:
- 在ImageNet中预训练网络时,使用的输入是
224*224,用于检测任务时,输入大小改为448*448,这是通过调整第一个卷积层的步长来实现的; - 网络的设计借鉴了GoogLeNet,使用了很多
1*1的卷积层来进行特征降维; - 最后一个卷积层的输出为
(7, 7, 1024),经过flatten后紧跟两个全连接层,形成一个线性回归,最后一个全连接层又被reshape成(7, 7, 30),形成对2个box坐标及20个物体类别的预测(PASCAL VOC)(源码中实际上是预测了3个box->7*7*35)。
3. YOLO如何进行预测?
引用这篇文章中的图片来解释这个问题。
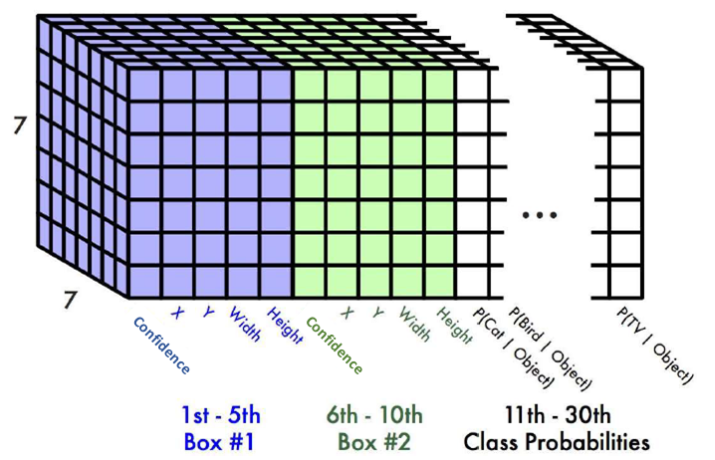 如上图所示,这就是最后一层全连接经过reshape之后的
如上图所示,这就是最后一层全连接经过reshape之后的(7, 7, 30)的张量,这张图需要结合论文中所述的Grid Cell来理解。
我们知道,YOLO网络输入的是448*448的正方形图片,最终输出的是一个7*7的特征图,下采样倍数为64倍,在输出的7*7的特征图上,每个格点对应原图中一个64*64的区域,也就是论文中所述的Grid Cell。
在上面的图片中,7*7特征图中的每一个格点都是一个1*30的向量,格点对应原图中的一个64*64的Grid Cell,格点中的参数就是对以该Grid Cell中心的物体类别和bounding box的预测,因此很容易理解,对一张图片,每个格点预测一个物体类别和两个bounding box,这里要注意,每个格点的两个bounding box预测的是同一类物体,要是分别负责预测不同物体,则最后一层的shape应该为7*7*(2*(5+20))=7*7*50(YOLOv2)。
论文中有这样的描述:
If the center of an object falls into a grid cell, that grid cell is responsible for detecting that object.
对该描述的理解为:在训练阶段,图片中物体的truth box已知,这些box可映射到7*7的特征图的某一个格点上(这也就是计算loss中$I_{ij}$),在训练时,某一个truth box仅由特征图上对应的格点的2个bounding box中与其iou较大的box(记为best box)进行预测,也即在计算loss时,仅计算该best box和相应的truth box之间的坐标损失,这也就是论文中所述的,所在物体中间的格点负责预测该物体。
4. 如何理解YOLO的loss function?
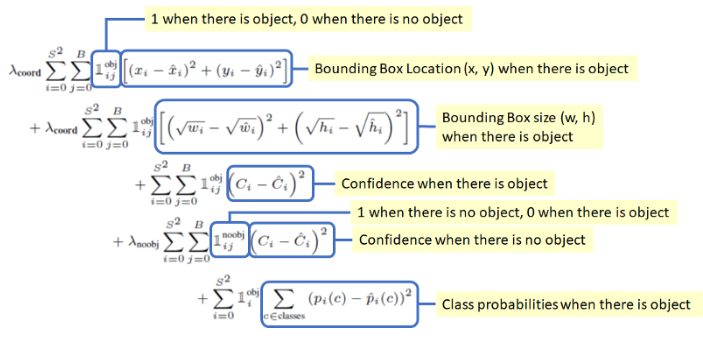 依然借用这篇文章中的图片来进行解释。
论文中所说的把目标检测作为一个回归问题,最明显的就是把bounding box的坐标误差作为loss进行计算,从而达到直接使用网络回归出正确的bounding box位置的目的。
Loss的计算总体上可分为两部分,即box的loss
依然借用这篇文章中的图片来进行解释。
论文中所说的把目标检测作为一个回归问题,最明显的就是把bounding box的坐标误差作为loss进行计算,从而达到直接使用网络回归出正确的bounding box位置的目的。
Loss的计算总体上可分为两部分,即box的lossx, y, w, h, confidence和类别的loss,对box的loss,又可根据当前box中是否包含物体来分别进行计算。
在计算box的loss时,程序遍历每一个格点的每一个box(根据论文中所述,YOLOv1中每张图片应该是7*7*2=98个box),若当前box中有物体(有truth box投影到当前格点,且该box是当前格点所预测的box中与truth box的iou最大的),则计算该box与truth box的x, y, w, h, confidence误差,对没有物体的box,则只计算confidence误差。
在计算类别的loss时,程序遍历每一个格点,若当前格点中包含物体,则计算类别误差,否则不计算。
这里要注意以下几点:
- bounding box的
w,h是相对原图的一个比例值,范围为[0, 1]; - bounding box的
x,y坐标是相对某一个格点的偏移,范围为[0, 1],这里解释如下: 在训练时, truth box的x,y坐标首先被转换为相对原图的比例信息,然后根据下面的公式转换为相对某个格点的偏移信息:// S=7 => (row, col)是truth box所对应的格点的位置 int col = (int)(x*S); int row = (int)(y*S); // (x, y)是truth box相对(row, col)格点的偏移 [0, 1] x = x*S - col; y = y*S - row;因此,由这样的truth box参数回归得到的bounding box的
x,y坐标就是相对某一格点的偏移; - 为了增加有物体的box的loss在总的loss中的比重,作者为有物体的box的loss和没有物体的box的loss分别设了不同的权重。
5. YOLO的性能如何?
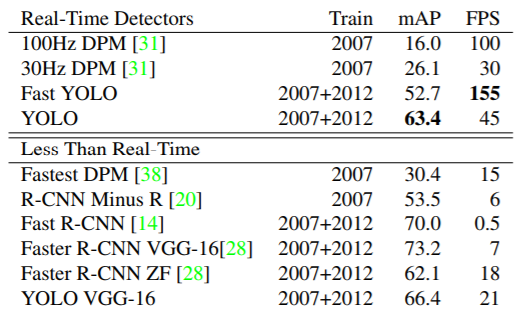 使用PASCAL VOC 2007+2012数据集训练的YOLO,在相同精度上比其他方法要快很多,达到了实时性(15FPS?)
使用PASCAL VOC 2007+2012数据集训练的YOLO,在相同精度上比其他方法要快很多,达到了实时性(15FPS?)
6. YOLO还有哪些不足?
- 图像下采样64倍,容易漏检小物体;
- 每张图像仅预测出98个bounding box,且每个格点的bounding box负责预测的是同一个物体,若一幅图中有多个物体都落入同一个格点,则只能预测其中的一个,使得算法召回率不高;